1. 들어가며
지난 8월, ML2의 이채혁 님과 윤세현 님이 한국에서 열린 Conference on Robot Learning (CoRL) 2025에 다녀왔습니다. 마침 저희 사무실 바로 옆인 코엑스에서 학회가 열렸기도 하고, 감사하게도 회사에서 (매우 비싼) 등록비를 지원해주셔서 다녀올 수 있었습니다.


코엑스에서 열린 CoRL 2025. 아직 개회 전이라 조금 한산합니다.
오후의 포스터 세션에는 사람이 많아졌습니다!
2. 문제는 데이터셋
이번 CoRL 2025에 대한 저의 인상을 한 마디로 요약한다면, “문제는 데이터셋” 이었습니다. 데이터셋 연구의 수가 가장 많은 것은 아니었지만, 어떤 연구의 인기가 가장 많았느냐를 묻는다면 단연 데이터셋 연구였습니다. (숫자 상으로 가장 많은 것은 manipulation 연구, 그 중에서도 grasping 연구가 가장 많았습니다.) CoRL은 모든 연구에 대해 각자의 포스터 발표 공간이 주어지는데, 특히 데이터셋 연구 포스터에는 늘 청중이 모여들었습니다.
제가 봤던 흥미로웠던 데이터셋 연구를 몇가지 소개합니다. 개인적으로 이번 학회에서 가장 재미있었던 논문이기도 한 “VideoMimic: Visual Imitation Enables Contextual Humanoid Control” 1 은 UC Berkeley에서 발표한 논문입니다. 짧게 요약하면 영상으로부터 데이터를 추출하여 시뮬레이터에서 그 영상을 그대로 재현하는 과정을 구현한 연구입니다. 영상에서는 이미지 데이터만을 얻을 수 있지만, 이 영상을 시뮬레이터로 옮기면, 힘, 속도, 마찰력과 같은 물리 데이터를 얻을 수 있고, 해당 영상에 대한 카메라 시점도 자유롭게 바꿀 수 있다는 큰 장점이 있습니다. 이 논문은 제가 느끼기에 포스터 세션에서 가장 인기 있는 연구이기도 했고, Best Student Paper Award를 수상하면서 그 퀄리티를 입증하기도 했습니다. “Generating Robot Constitutions & Benchmarks for Semantic Safety” 2 논문은 Google DeepMind에서 나온 논문으로, 아기가 로봇에 접근하는 것과 같은 위험한 상황에 대한 데이터셋은 수집할 수 없기 때문에, 이러한 위험 상황에 대한 데이터셋을 생성 모델로 만든다는 내용이 주요 포인트였습니다. “Phantom: Training Robots Without Robots Using Only Human Videos” 3 은 Stanford University에서 발표한 논문으로, 사람의 시연 영상을 생성 모델을 이용해 로봇 시연 영상으로 바꾼다는 아이디어를 제시했습니다. 도메인을 다르지만 저희 팀에서도 비슷한 접근을 한 적이 있어 흥미로웠습니다.

VideoMimic 연구의 포스터 세션. 정말 인기가 많아서 질문 하나 하기가 어려웠습니다.
논문들 외에 세션에서도 데이터셋이 많이 언급되었습니다. 키노트에서는 MIT의 김상배 교수님이 왜 자율주행보다 manipulation에서의 데이터셋이 얻기 어려운지 강조해서 설명했고, UIUC의 Wenzhen Yuan 교수님 또한 tactile 센서 개발에서 실제 데이터셋을 얻기 어려워 시뮬레이터를 개발한 경험을 자세히 소개했습니다. 패널 토크에서도 Nvidia의 연구원인 Scott Reed는 완전한 휴머노이드로 가는 길의 병목이 비디오 데이터셋의 부족이라는 견해를 밝혔고, Agility Robotics의 CEO인 Jonathan Hurst도 비슷한 취지로 더 나은 시뮬레이터가 필요하다고 언급했습니다. 데모룸에서 딸기 수확 로봇에 대해 자세한 설명을 해주신 대동로보틱스 분들도 대동로보틱스의 로봇 시스템이 텔레오퍼레이션을 통한 데이터셋 수집을 위한 것이라고 설명해주셨습니다.

MIT 김상배 교수님의 발표 중. 왜 manipulation을 위한 데이터셋을 모으는 게 이렇게 힘든가?
그렇다면 이 부족한 로봇 데이터셋 문제를 어떻게 해결할 수 있을까요? 학회에서 제시된 의견은 크게 네 가지 방향으로 나뉘었습니다. 첫 번째는 모델 기반 접근(Model-based approach) 입니다. MIT 김상배 교수님의 발표에서도 언급된 연구들로, 자동반사 동작(reflex actions)과 같은 인간의 기본적인 움직임을 모델링해 제한된 데이터셋으로도 안정적인 제어가 가능하도록 만드는 방향입니다. 즉, 데이터가 부족해도 모델이 이를 보완해 주는 방식입니다. 두 번째는 시뮬레이션 활용을 극대화 하는 방법입니다. 기존 영상 데이터를 시뮬레이션 환경으로 변환해 더 많은 물리 데이터를 생성하거나, 시뮬레이터 자체를 고도화해 현실감을 높이는 등 시뮬레이터를 적극 활용하는 연구들이 소개되었습니다. 세 번째는 생성 모델을 이용해 데이터셋 자체를 생성 하는 접근입니다. 생성 모델의 발전 덕분에 실제처럼 보이는 데이터를 만들어내어 학습 데이터로 활용하는 사례가 점점 늘고 있습니다. 마지막 네 번째는 텔레오퍼레이션을 통한 데이터 수집 입니다. 사람이 직접 로봇을 조작해 시뮬레이션과 실제 환경에서 고품질 데이터를 대규모로 수집하는 방식입니다. 최근 산업계에서도 매우 활발하게 시도되고 있습니다.

생성 모델로 수집하기 어려운 데이터셋을 만드는 구글의 연구 2
아직 로봇 데이터셋 문제는 명확한 정답이 없는 열린 연구 분야이며, 앞으로도 다양한 실험과 새로운 접근이 계속 등장할 것으로 기대됩니다.
3. Panel Talk. 휴머노이드란 무엇인가?
개인적으로 학회에 가면 가장 흥미롭게 듣는 세션이 패널 토크입니다. 올해 CoRL은 Humanoids 2025 학회와 공동 개최된 만큼, 패널 토크의 주제 역시 자연스럽게 휴머노이드에 집중되었습니다.

이번 CoRL 2025의 패널 토크과 연사진들
휴머노이드의 정의에 대한 다양한 관점이 오갔는데, 그중 가장 공감이 갔던 정의는 Agility Robotics의 CEO인 Jonathan Hurst의 “사람 인터페이스의 높이에 대응할 수 있는 형태를 가진 로봇” 이라는 의견이었습니다. 초인종, 문 손잡이, 스위치, 부엌 도구 등 사람이 주로 조작하는 물체들은 모두 손이 쉽게 닿을 수 있고 눈높이에서 쉽게 확인할 수 있는 높이에 위치해 있습니다. Jonathan Hurst는 이족 보행이 이러한 인터페이스 높이에 가장 효율적으로 접근할 수 있는 형태라고 설명했고, 그것이 Agility Robotics가 이족 보행 형태를 선택한 이유라고 밝혔습니다. 사람 환경에서 그대로 활용하기 위해 사람 형태을 가진 로봇이 필요하다는 말은 많이 들어봤지만 약간 막연한 느낌이 있습니다. 하지만 이렇게 사람 인터페이스의 “높이” 에 최적화한다는 설명은 신선하면서도 구체적인 최적화 목표를 제시함으로써 설득력이 있었습니다.
조금 민망하지만, 매년 빠지지 않고 등장하는 멋진 주장도 있습니다. 진정한 인공지능을 구현하려면 인간의 신체 구조가 필요하다는 이야기입니다. ‘풀메탈패닉’ 같은 소설에서도 등장하는 관점인데, 실제로 얼마나 타당한지는 아직 판단하기 어렵습니다. 하지만 저는 ‘풀메탈패닉’ 소설의 팬이기에, 이 의견에도 손을 들어봅니다. ^^
휴머노이드 개발의 가장 큰 병목이 무엇이냐는 질문에는 여러 대답이 나왔지만, 그중 특히 인상적이었던 것은 중국의 휴머노이드 전문 기업인 Galaxea의 답변이었습니다. 이들은 가장 큰 병목으로 “과열 문제가 없는 하드웨어(Less overheated hardware)” 를 꼽았는데, 살짝 농담처럼 얘기했지만 실제 로봇을 제작하고 다양한 환경에서 운용해본 경험이 없으면 나오기 어려운 현실적인 답변이었습니다. 저 역시 예전에 매니퓰레이터 로봇을 제작할 때 과열 문제로 예상보다 큰 어려움을 겪었던 경험이 있어 크게 공감할 수 있었습니다. 이 답변만으로도 중국에서 로봇 하드웨어 분야에서 얼마나 많은 시행착오를 거치며 기술을 축적하고 있는지 간접적으로 느낄 수 있었습니다. 실제로 데모룸에서도 중국 휴머노이드 기업이 압도적으로 많았고, 하드웨어 완성도 역시 상당히 높아 보였습니다. 물론 지금 존재하는 많은 기업이 앞으로 시장에서 사라질 수도 있겠지만, 이런 경쟁 속에서 살아남는 기업들은 그만큼 더 단단한 기술력을 갖추게 될 것이라는 생각이 들었습니다.

정말 많았던 중국의 휴머노이드 회사들 (한국 회사도 있습니다!)
4. VLM으로 많은 것이 가능해진 Navigation
전체 논문 중 내비게이션 연구는 약 4% 정도로 매우 적었습니다. 내비게이션을 연구하고 있는 입장에서 조금 아쉬운 부분이었지만, 그중에서도 VLM(Visual Language Model) 덕분에 기존 방식으로는 어려웠던 문제들이 가능해지고 있다는 점이 눈에 띄었습니다.
사람은 운전을 하거나 실내에서 길을 찾을 때, 간판이나 방향지시표의 텍스트를 읽고 이를 적극적으로 활용해 이동 경로를 결정합니다. 하지만 이는 로봇에게는 어려운 기능인데, 특히 차량 자율주행과 달리 로봇이 주로 배치되는 실내 환경에서는 간판과 방향지시표의 형태가 제각각입니다. 텍스트만으로는 광고 등도 함께 인식되기에 의미를 파악하기 어렵고, 방향지시표나 간판에는 규격화된 양식이 없어 기존 object detection 모델을 학습시키는 것이 쉽지 않습니다.
하지만 VLM은 이러한 문제를 새로운 방식으로 접근합니다. 간판이나 텍스트를 주변 환경까지 고려하여 문장이나 임베딩 벡터로 자세하게 표현할 수 있고, 이미 방대한 양의 문자와 이미지로 학습을 했기 때문에 별도의 추가 과정 없이도 무엇이 내비게이션에 필요한 텍스트인지 판단할 수 있습니다. 이로 인해 기존에는 식별이 어려웠던 다양한 표식도 처리할 수 있게 되었습니다. “Human-like Navigation in a World Built for Humans” 4 가 이번 CoRL에서 나온 비슷한 방향의 대표적인 연구입니다.

“Human-like Navigation in a World Built for Humans” 연구의 포스터 세션
그렇지만 이러한 VLM 기반 접근에도 한계는 여전히 존재합니다. 무엇보다 VLM은 많은 전력을 소모하는 GPU 서버 위에서만 실행이 가능하기 때문에, 이미지를 네트워크로 전송하고 서버에서 VLM을 실행해 결과를 받아야 한다는 점입니다. 개인적으로 로봇이 네트워크에 의존하게 되면 배치 가능한 환경 자체가 제한된다고 보고 있습니다. 특히 SLAM처럼 실시간 영상 처리 성능이 중요한 경우에는 대역폭과 지연 문제로 인해 이러한 방식은 더 큰 제약을 갖게 됩니다. 결국 중요한 것은 VLM의 성능을 유지하면서도 로봇 자체에서(on-device) 실행할 수 있도록 만드는 것이며, 앞으로 내비게이션 분야가 해결해야 할 핵심 도전 과제라고 생각합니다.
5. 한 연구 그룹의 Tactile 센서에 대해서
이번 학회의 두 번째 키노트 발표는 UIUC의 Wenzhen Yuan 교수님 연구 그룹 이었는데, 사실 이 그룹의 연구는 제가 몇 년 전부터 꾸준히 팔로우해오던 분야였습니다. 아직 AI가 지금처럼 폭발적으로 주목받기 전, 매니퓰레이션 연구가 소수의 전문 연구자들만 참여하던 시절부터 이들은 일관되게 tactile 센서 를 연구해온 팀입니다.
이들의 방식은 간단히 말하면 “카메라 기반 tactile 센싱” 입니다. 얇은 실리콘 패드에 물체가 닿으면 패드가 변형되는데, 그 변형을 내부 카메라로 촬영하여 접촉면의 고해상도 정보를 얻는 방식입니다. 카메라를 사용하기 때문에 아주 미세한 변화까지 감지할 수 있다는 것이 큰 장점입니다. 5
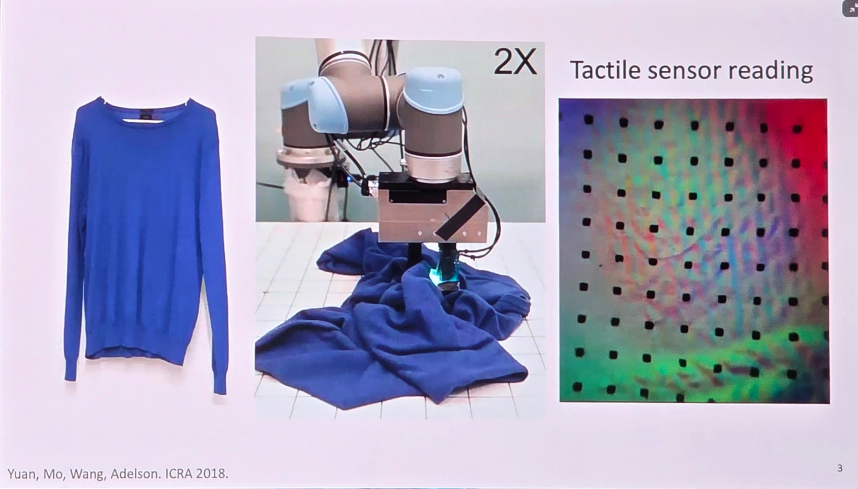
카메라 기반의 tactile 센서
지금은 이들이 제시한 촉각 센서 방식이 대부분의 grasping 연구에서 사실상 표준 이 되었습니다. 또한 단순히 센서를 만드는 데서 멈춘 것이 아니라, 촉각 데이터셋 생성을 위한 tactile 시뮬레이터, 신호 처리를 위한 딥러닝 기반 기법 등 다양한 기술을 지속적으로 접목하며 생태계 전체를 함께 구축해 왔습니다.

시뮬레이터까지 센서를 위한 생태계를 조직해왔습니다.
아무도 크게 주목하지 않던 분야에서 하나의 아이디어와 하드웨어로 시작해, 꾸준히 기술을 쌓아가며 결국 메인스트림이 된 과정은 그 자체로 많은 영감을 주었습니다. 하나의 문제에 깊게 집중하고, 새로운 기술을 끊임없이 흡수하며 확장해 나가는 태도의 중요함을 다시 한번 느낄 수 있었습니다.
6. 마치며
최근 빅테크들의 감원 소식이 이어지는 와중에도, CoRL의 채용 부스는 매우 활발했습니다. 구글이나 Nvidia와 같은 대형 기업들의 적극적인 참여가 두드러졌고, 부스와 데모도 제대로 준비해서 나온 듯한 모습이었습니다. 다른 더 큰 규모의 로보틱스 학회들인 IROS나 ICRA와 비교해 보더라도, AI와 로보틱스가 융합된 이 분야가 지금 가장 많은 인재와 투자가 몰리는 영역이라는 사실을 다시 한번 실감할 수 있었습니다.


1. 구글의 VLA 모델인 Gemini Robotics 1.5의 시연
2. Nvidia는 정말 채용에 진심이었습니다! (이력서를 제출하지 않으면 굿즈를 받지 못했습니다…)
7. 참고문헌
[1]
Arthur Allshire*, Hongsuk Choi*, Junyi Zhang*, David McAllister*, Anthony Zhang, Chung Min Kim, Trevor Darrell, Pieter Abbeel, Jitendra Malik, Angjoo Kanazawa. “VideoMimic: Visual Imitation Enables Contextual Humanoid Control”. CoRL, 2025.
[2]
Pierre Sermanet, Anirudha Majumdar, Alex Irpan, Dmitry Kalashnikov and Vikas Sindhwani. “Generating Robot Constitutions & Benchmarks for Semantic Safety”. CoRL, 2025.
[3]
Marion Lepert, Jiaying Fang, Jeannette Bohg. “Phantom: Training Robots Without Robots Using Only Human Videos”. CoRL, 2025.
[4]
Chandaka, Bhargav and Wang, Gloria and Chen, Haozhe and Che, Henry and Zhai, Albert and Wang, Shenlong. “Human-like Navigation in a World Built for Humans”. CoRL, 2025.
[5]
Wenzhen Yuan, Yuchen Mo, Shaoxiong Wang, and Edward H. Adelson. “Active Clothing Material Perception Using Tactile Sensing and Deep Learning”. ICRA, 2018.







