
Neural Architecture Search (이하 NAS) 와 AutoML 분야에 대한 연구가 활발해지는 가운데, 작년에 등장한 Differentiable Architecture Search (이하 DARTS) 논문에서는 architecture search을 기존과는 다른 방법으로 접근하여 많은 연구자들의 뜨거운 관심을 받았다. DARTS architecture는 실제로 어떻게 최적의 architecture를 찾아갈까? 그리고 이러한 방법으로 찾는 architecture가 얼만큼의 성능을 보여줄수 있는가? 이 포스트에서는 DARTS에서 제시한 설계 방식의 이해와 실제로 찾는 architecture는 어떻게 만들어지는지를 설명하고, 그리고 궁금한 부분들을 검증하기 위한 실험결과를 정리하였다. 이를 위해 DARTS를 pytorch로 구현, 논문에 나타나지 않은 작동방법의 세세한 부분까지 명확한 접근을 위해 기존의 DARTS 저자의 코드를 참고하여 구현하였으며, convolutionl neural networ (이하 CNN) architecture의 도출과정을 토대로 실험을 진행하였다.
1. DARTS search process
Search process
지금까지의 NAS계열은 operation을 무엇으로 선정하는지를 직접 선택해서 비교해보는 이산적인 방법으로 풀었다. 그런데 DARTS에서는 다음과 같이 연속변수로서 풀어간다.
- path에서 사용할 operation의 선택확률를 특정할 수 있는
를 가중합하는 커다란 단일 architecture를 정의하고, 이 architecture에 손실을 최소화 하기위한 학습을 진행하며, 여기서 성능향상에 도움이 되는 operation의 값을 높여주면서 적절한 쪽으로 수렴시킨다. - 위 과정이 끝나면 각 노드에서 input operation중
를 크기순으로 k개만 남겨서 architecture를 단순화하고 최종architecture를 도출한다.

(먼저 이해를 위해 논문에서 예시로 보여준 왼쪽 그림 1 을 오른쪽 그림으로 다시 표현했다.)

(위 그림에서 주황색 실선은 노드간의 path를 보여주며, 하나의 path는 search 과정에서 사용하는 operation들의 집합이다.)
-
값? 

Algorithm 1: DARTS
Create a mixed operation
while not converged do
- Update architecture
by descending
- Update weights
by descending
Derive the final architecture based on the learned
-
최종 architecture에 사용할 operation을 선택하는 방법

학습중일때 이전 epoch에서 해당 architecture operation들의 가중치와 기존
를 참고하여 다음 epoch architecture의 값을 계산하고, 노드의 기준에서 input operation을 의 크기순으로 선택해서 k개만 남겨 architecture를 확정한다.
-
전체 architecture가 아닌 cell architecture를 찾는것
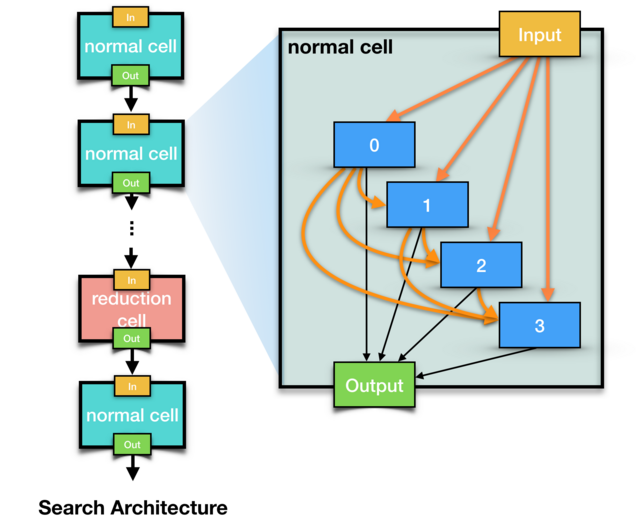
앞에서 찾아낸 architecture는 하나의 cell architecture이다. search에서 활용한 architecture는 이 cell을 n개의 레이어형태로 연결한 것이다.
값이 입혀진 operation set을 모두 사용하는 cell을 재료로 하기때문에 search에서 사용하는 전체 architecture는 매우 크고 무거워진다. 하지만 이 과정을 통해 찾아낸 cell은 가 정의된 search용 cell보다 훨씬 간결하다. 
이렇게 search된 cell architecture를 통해 레이어를 쌓아서 모델을 최적화 하면 search 때보다 가벼우면서 더 높은 성능으로 만들 수 있다. 물론 search 단계와 최적화 단계의 전체 architecture를 다르게 작성할 수도 있다. search때와 비교했을때도 epoch당 학습도 빠르게 진행되고, architecture만 잘 구성하면 최고 수준의 성능도 기대해볼만하다.
Search시 알고 있으면 좋은것들
-
Cell의 두가지 종류 (normal & reduction)

DARTS에서는 process에서 두개의 cell architecture를 사용한다. normal cell과 reduction cell이다. 전체 레이어수를 지정하면 대부분의 레이어는 normal cell을 사용하게 되고, 두개의 reduction cell이 중간에 삽입된다. normal cell은 입력값과 출력값의 feature 사이즈가 동일하고, reduction cell은 전체 연결의 1/3, 2/3 지점에 배치되어 feature 사이즈는 줄이는 polling같은 역할을 한다.
왜 reduction cell을 적용했을까? 일단 feature 사이즈의 수축을 유도하여 모델의 전체 사이즈를 줄일 수 있다는 장점이 있다. 그리고 수축이 랜덤하게 발생할경우 architecture의 forward를 수행하기가 곤란해지는데, 이를 수축이 일어날 위치를 레이어로 강제지정하여 문제를 해결할 수 있다.
-
레이어와 노드 그리고 feature 사이즈

(operation별
값의 추이 그래프) 만약 레이어나 노드수를 너무 과하게 지정할 경우 path의
값이 none(zero)에 집중되는 양상을 보인다. 그래서 사용되는 데이터의 사이즈(이미지크기)에 맞춰 레이어와 노드의 개수를 조정할 필요가 있다. 입력 데이터의 크기에 비해 너무 깊고 복잡한 architecture를 찾게되면 cell architecture 자체를 가볍게 하는 경향을 보인다. 그래서 search과정의 초반 epoch때 none으로 수렴하는 path가 너무 많다면 레이어와 노드의 수를 조절할 필요가 있다. 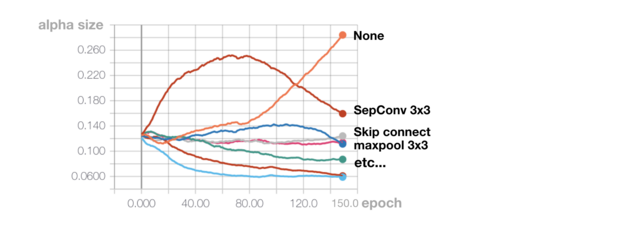
그러나 normal cell은 아무리 조절을 잘해도 none operation으로 수렴하려는 경향이 발생한다. 어떻게 해야 할까?

값이 높은 edge가 항상 최선이라고 볼 수는 없다. 특히 none edge를 선택했을때 더욱 그렇다. 앞에서도 언급했지만 search과정 중 epoch을 과하게 진행시키면 none의 값을 크게 주는 경우가 많다. 그래서 none의 값이 가장 큰 경우엔 none operation를 고려하지 않고 차순위의 edge를 선택하게 한다. 예를 들어 none edge의 값이 0.5이고 다른 edge의 값이 [0.15, 0.13, 0.11, 0.08, 0.01]인 상황이라면 최대 값이 none 이므로 이것은 무시하고 0.15를 가진 edge를 차선으로 선택하는것이다. 이 방법이 괜찮은 이유는 모든 edge를 none으로 선택하게되는 최악의 상황도 막을 수 있기 때문이다. none을 무시한다면 레이어와 노드수는 키워도 괜찮은거 아닌가 싶을수도 있을것이다. 그러나 이 과정에서
의 크기가 none operation으로 쏠려서 비대해지면 나머지 operation 에 분배되는 값은 매우 작아져서 상호 비교가 무의미해지게 된다. 이 상황에서 데이터 시드를 바꾸고 search하면 cell architecture가 일정하지 않게 나올 수 있다. (이것은 뒤에서 다시 언급하겠다.)
-
적절한 search epoch 선정
DARTS에서 search epoch을 늘린다고 해서 무조건 유의한 architecture가 도출되는것은 아니다. 적정한 epoch때 도출된 cell architecture가 더 나은 성능을 보이기도 하기 때문이다. (이 부분은 뒤의 실험정리에서 설명)
architecture를 형성할때는 입력값을 바로 받는 노드와 다른 노드의 출력을 받는 종속된 노드가 생성된다. 이때 종속된 노드의 경우는 이전 노드의 변화에 따라서 유의한 edge가 계속 변화하는 양상을 보인다. 그런데 search과정 중 성능개선이 더 이뤄지지 않고 있는 상황일때도값은 멈추지 않고 수렴하려는 경향을 보인다. 가중치의 값이 끊임없이 변화하고 이미 이전에 다른 architecture일때 학습된 내용 때문에 계산이 영향을 받아 특정 edge의 값만 계속 비대해지는 경향이 생긴다. 언제 epoch을 중단하는것이 좋다고 확실히 정하진 못하겠지만, 대략 search 과정중 학습 성능이 충분히 좋고 과적합도 크지 않다고 판단되었을때 최종 architecture를 도출 하는것이 좋지 않나 생각한다. 이와 관련한 글쓴이의 추가적인 제안은 아래에서 제시하겠다.
2. Results from train/test
이미지와 관련한 architecture를 찾는것을 위주로 진행했다. CIFAR10을 기준으로 search한 결과를 보자.
🏁 Results (The average value of the results)
Original Paper
GPU : GTX 1080Ti
| mode | runtime | test acc | params |
|---|---|---|---|
| DARTS(first order)+cutout | 4day | 97.0% | 3.3M |
| DARTS(second order)+cutout | 4day | 97.24% | 3.3M |
Our Experiments
environment = GPU : Titan V(Single), py3.6 ,cuda10, torch 1.0
| mode | runtime | train acc | val acc | params | 레이어s | epochs | base search env |
|---|---|---|---|---|---|---|---|
| Search | 29hr | 99.9% | 89%~92% | - | - | 100~150 | batch_size=64 |
| Test1 | 8hr | 98.6% | 96.7% | 2.2M | 16 | 300 | search(노드4, 레이어8) |
| Test2 | 18hr | 96.9% | 97.04% | 2.5M | 16 | 500 | search(노드3, 레이어2) |
| Test3 | 23hr | 97.1% | 97.01% | 3.2M | 16 | 500 | search(노드4, 레이어2) |
| Test3-1 | 23hr | 97.5% | 97.07% | 3.3M | 16 | 500 | search(노드4, 레이어3) |
| Test4 | 24hr | 98.97% | 97.23% | 2.9M | 16 | 600 | search(노드4, 레이어8) |
| Test5 | 30hr | 99.3% | 97.34% | 3.5M | 16 | 700 | search(노드4, 레이어8) |
| Test6 | 14hr | 97.2% | 96.98% | 1.8M | 8 | 500 | search(노드5, 레이어3) |
| Test6-1 | 21hr | 97.56% | 97.14% | 2.6M | 12 | 500 | search(노드5, 레이어3) |
| Test7 | 14hr | 97.91% | 97.03% | 2.2M | 12 | 500 | search(노드5, 레이어4) |
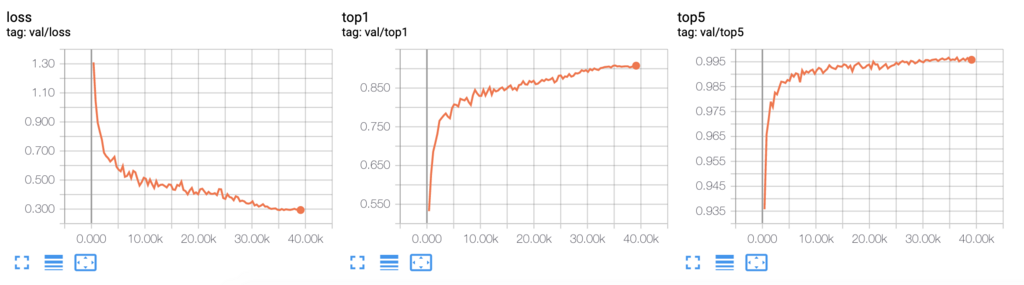
-
특징 1. search과정에서의 성능
search는 100epoch기준으로 29시간이 걸렸으며, 최종 학습과 검증의 차이가 8~9%정도 차이를 보이며 약간의 과적합 현상이 있다. 검증 정확도도 91%대로 나쁘지 않은 성능을 보여준다.
-
특징 2. 최적화 학습시 search architecture보다 더 높은 성능을 기록함
도출된 architecture를 토대로 최적화를 시키면 search과정때보다 과적합이 확실히 줄어들게 된다. 특정 cell architecture들은 검증 정확도가 97%대를 기록하기도 한다. epoch을 더 늘리거나 파라미터 조정을 통해 더 뛰어난 성능의 architecture를 도출할 수 있다.
3. Experiments and Insights
몇가지 궁금한 점이 있어 정리해 보았다.
- 하나의 architecture로 수렴한다면 셔플링된 데이터셋으로 학습해도 같은 architecture로 수렴할것인가?
- search에서 정의한 레이어와 노드의 개수가 적정한지 어떻게 판단할까?
가 과적합되거나 극소점로 빠지는것은 아닐까? - search 중간에 나온 architecture를 처음부터 학습하면 마지막에 도출된 architecture보다 성능이 좋을수 있나?
1. 하나의 architecture로 수렴한다면 셔플링된 데이터셋으로 학습해도 같은 architecture로 수렴할것인가?

-
➞ 비슷한 architecture로 수렴하지만 똑같지는 않다.$\alpha$ 값의 추이는 얼추 비슷하더라도 노드기준으로 k개의 입력 operation만 선택하는 방법을 사용하기 때문에 하위 노드일수록 시드마다 조금씩 변동이 있다. 특히 레이어와 노드수가 데이터 크기에 비해 너무 많으면 $\alpha$ 값의 미미한 차이때문에 의미없는 operation을 선택할 가능성도 있다. 따라서 적절한 레이어 및 노드갯수를 배치하여 찾아내는것도 중요한데, 관련한 내용은 밑에서 다루겠다.
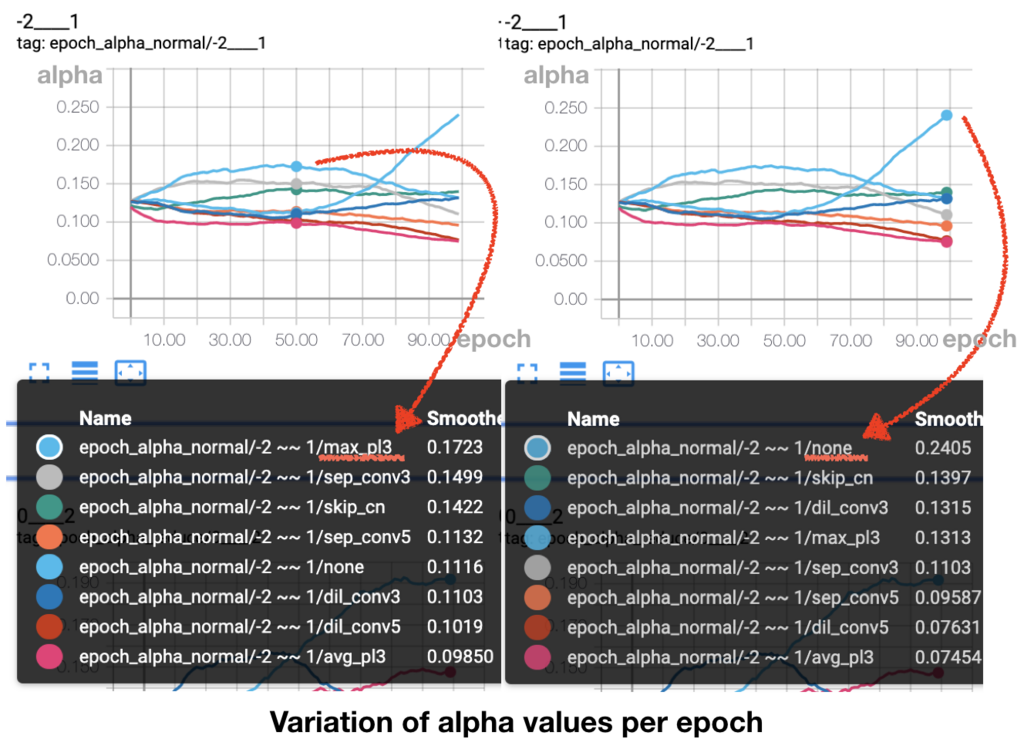
2. search에서 정의한 레이어와 노드갯수가 적정한지 어떻게 판단할까?

(normal cell에서 특정한 operation의
-
search과정을 진행하다보면 입력값이외의 다른 노드로 부터 입력값을 받는 노드의 경우 none의
값을 처음부터 높이는 경우가 있다. 이런 상황은 노드의 개수와 레이어수가 많을때 발생했는데, 1번 질문에서 언급했던 최적의 architecture를 도출하지 못하는것은 아니지만 그 architecture의 일관성이 떨어지는 양상을 보였다. 물론 평가성능이 비교적 떨어지는 경우도 존재했어도 크게 문제가 있을 정도는 아니었다. 하지만 노드의 수가 많아지거나 레이어를 크게 잡으면 컴퓨팅파워를 너무 크게 잡는 문제가 있고, 너무 깊고 복잡한 레이어 수로 인한 문제도 있다. 
-
그래서 특정한 기준으로 적정성을 판단하는 것이 필요하다. 여기서 블로그 글쓴이는 다음과 같은 기준을 제시하고자 한다.
- search과정중 normal cell에서 50epoch일때, 마지막노드의 모든 입력 operation
값이 none을 최대로 한다. - 마지막 노드의 직전 노드는 입력값이 하나라도 none을 선택하지 않아야 한다.
- 50epoch은 글쓴이의 실험적인 경험일 뿐, 더 이전이나 이후의 epoch을 기준으로 정해도 무방하다.
- 위의 조건들을 충족하면 노드수와 레이어수가 적절하게 배치되었다고 결정한다.
- search과정중 normal cell에서 50epoch일때, 마지막노드의 모든 입력 operation
-
실험적으로 none을 입력값의 최대로 가지는 노드가 아예 없으면 성능이 충분히 발현되지 않았고, none을 입력값으로 가지는 노드가 너무 많으면 search시에 오래걸리면서 도출되는 architecture도 일관성이 없기 때문에 기준을 이렇게 제시했다.
값이 위의 그림처럼 나타나는 경우엔 레이어가 너무 많아서 일어나는 현상으로 보고 레이어수를 조절했다.
3.
-
➞ Search단계에서
가 극소점으로 빠지는것을 걱정할 필요는 없다. - 이유는 search에서는 명확한 architecture를 찾는것이 아닌 어떤 종류의 edge가 더 유효한지를 찾고 가장 유효한 edge를 선택하는 것이므로 극소점이 존재하여 여기에 빠져도 전체적인 흐름을 헤치지는 않는것 같다. 여러 레이어로 중첩구성되어 있기에 최종 loss로 근접하는것에도 도움이 된다. (다만 레이어와 노드가 너무 비대하면 같은 데이터로 여러 종류의 architecture가 생성되니
도 극소점같은 개념이 존재할 것 같다)
- 이유는 search에서는 명확한 architecture를 찾는것이 아닌 어떤 종류의 edge가 더 유효한지를 찾고 가장 유효한 edge를 선택하는 것이므로 극소점이 존재하여 여기에 빠져도 전체적인 흐름을 헤치지는 않는것 같다. 여러 레이어로 중첩구성되어 있기에 최종 loss로 근접하는것에도 도움이 된다. (다만 레이어와 노드가 너무 비대하면 같은 데이터로 여러 종류의 architecture가 생성되니
-
를 쓰는것이 완벽한것은 아니다. - search단계에서 이미 학습이 된 모델을 재사용하면서
를 변화시키는데, 값이 변화할때마다 다른 노드에 미치는 영향이 즉각 반영되는건 아니다. epoch이 진행되면서 차차 그 영향이 전달되기때문이다. 게다가 최적화에 가까문 모델과 그렇지 않은 모델에서의 값의 변화는 분명히 다른데, 모델은 epoch이 진행될수록 최적화에 가까워지기 때문에 진행이 될수록 이미 최적화가 끝난 셋을 만들 가능성도 있다. 이것과 관련해서는 아래에서 더 다뤄보겠다.
- search단계에서 이미 학습이 된 모델을 재사용하면서
4. search 중간에 나온 architecture를 처음부터 학습하면 마지막에 도출된 architecture보다 성능이 좋을 수 있나?
-
이렇게 물어볼 수 있다. search process중 50epoch때 만들어진 architecture가 100epoch때의 architecture보다 성능이 좋을수 있는가? search과정을 몇 epoch일때 끊는게 가장 좋은가로 질문을 바꿔볼수도 있는데, 현재까지는 50~100epoch 사이의 search 과정중 학습 손실이 가장 작을때의 cell architecture가 평가에서도 최고성능을 냈다. 왜 그런지 이유를 보기 전에
값의 변화율을 먼저 보자. 
-
의 변화는 크게 2단계로 볼 수 있다. normal cell의 그래프를 보면 50epoch전후로 특정 operation이 최대치를 찍고 다른 operation이 치고 올라오는 경향을 볼 수 있다. 앞의 2번 질문에서 최적화되지 않은 모델과 최적화된 모델에서의 값 추이에 대해 이야기 했었는데 이것이 그것이다. 50epoch일때와 100epoch일때의 search architecture는 분명 성능차이가 있다. 성능이 충분히 좋아졌다면 해당 opeartion에 지속적인 가중치를 주지 않아도 이미 operation의 가중치만으로 충분할것이다. 그래서 해당 는 더이상 오르지 않고 여기서 더 성능을 개선할 수 있는 다른 operation에 가 더 분배된다. 그렇게 operation이 지속적으로 바뀌게된다. 그런데 값은 같은 path안에서 그 크기를 나눠가지기 때문에 다른 operation이 더 분배를 받게되면 기존의 잘되던 operation의 가중치가 급하게 떨어지는것 같다. (이번 실험에서는 100epoch를 넘어갈때는 대부분 architecture적 변화가 거의 없었다. 실험을 CIFAR10으로 진행했는데 데이터가 단순했기에 더이상의 최적화가 어려웠을것이다) -
실험에서도 최대의 성능을 발휘하는 operation이 대체로 결정이 된 이후로 architecture의 변화가 거의 없어졌다. 그래서인지 차이가 적은 비슷한 cel larchitecture가 이후 epoch에서도 계속 사용되면서 최종 평가의 결과도 크게 차이가 없었다.
4. Conclusion
A. 기존의 최고 성능급 분류모델들과 똑같지는 않지만 비슷한 architecture로 생성하는 형태를 보인다는 결론.
- Inception과 같이 cell의 architecture가 넓게 퍼졌다 모이는 모양으로 형성된다.
- edge중 3x3크기 conv의
값이 더 크게 나타난다.(깊이가 깊지 않다면 5x5도 선호하게 되지만, 최종성능이 잘 나오지는 못한다)
B. 특수한 architecture의 operation(edge)을 다른 종류의 것과 비교할때 활용이 가능
- sepConv을 유효하게 보는 양상이 있다. ➞ 현재 성능개선에 효과적이라고 알려진 conv종류 ➞
값으로 다른 edge종류들과 비교해볼 수 있었음
C. DARTS만의 독특한 사용법을 다른곳에서도 활용이 가능하다.
값의 조정으로 architecture를 변형하는 아이디어는 다른 탑다운 형태의 architecture를 지향하는 프로젝트에서도 유용하게 활용할 수 있을것으로 보인다.
D. 작성자의 생각
- 이런 과정을 거쳐서 도출된 cell architecture를 활용해서 다른 architecture로 재구현 하는방법이 최적 모델을 찾는 최선의 방법일까? 글쓴이는 일단은 좋은방법이라고 생각한다. 이미 이러한 cell architecture로 최적모델을 찾는 시도를 했던 프로젝트가 몇 있는데, ResNet이나 DenseNet도 그 한 종류이다. 그리고 이 방법이 괜찮다고 생각하는 또 다른 이유는 DARTS를 통해 생성되는 cell architecture는 성능이 잘 나올 수밖에 없는 특성을 갖추고 있기 때문이다. 왜냐하면 레이어 깊이면으로만 봐도 인셉션에 비교도 안될만큼 깊게 만든다. 모델의 깊이를 깊게만드는게 무조건 좋은건 아니지만, skip connection을 적극 활용한다는것과 operation을 가중합하는 과정에서 너무 저항이 큰 operation은 약해진다는 점에서 모델을 깊게 만들어도 괜찮다는 생각도 든다. (예제에서도 search과정에서는 8개 레이어를 사용했는데 모델최적화에는 두배가 넘는 16~20개 레이어를 써서 성능을 극대화하였다)
- DARTS에서 제시한 architecture search 방법을 실험하며 여러 흥미로운 점들을 다루어 보았고, 다른 DL 분야에서도 활용해봄직한 통찰을 얻을 수 있었던 시간이었다. 특히
값을 사용하여 여러 operation을 가중합하는 것은 여러 프로젝트에 적극 활용해볼 수 있는 좋은방법이 아닌가 생각한다.
참고
1
Hanxiao Liu et al. 2018, https://arxiv.org/abs/1806.09055
2
Ibid.
📑 DARTS paper: https://arxiv.org/abs/1806.09055
🚀 paper github codes: https://github.com/quark0/darts






