
1. Adversarial Attack and Defense
This post aims to cover main concepts from the paper "Where to be Adversarial Perturbations Added? Investigating and Manipulating Pixel Robustness using Input Gradients" by Hwang et al 1. The paper connects the gradients of input features to the robustness of a classification model, and shows that the robustness can be manipulated indirectly through changing the gradient flows within the model.
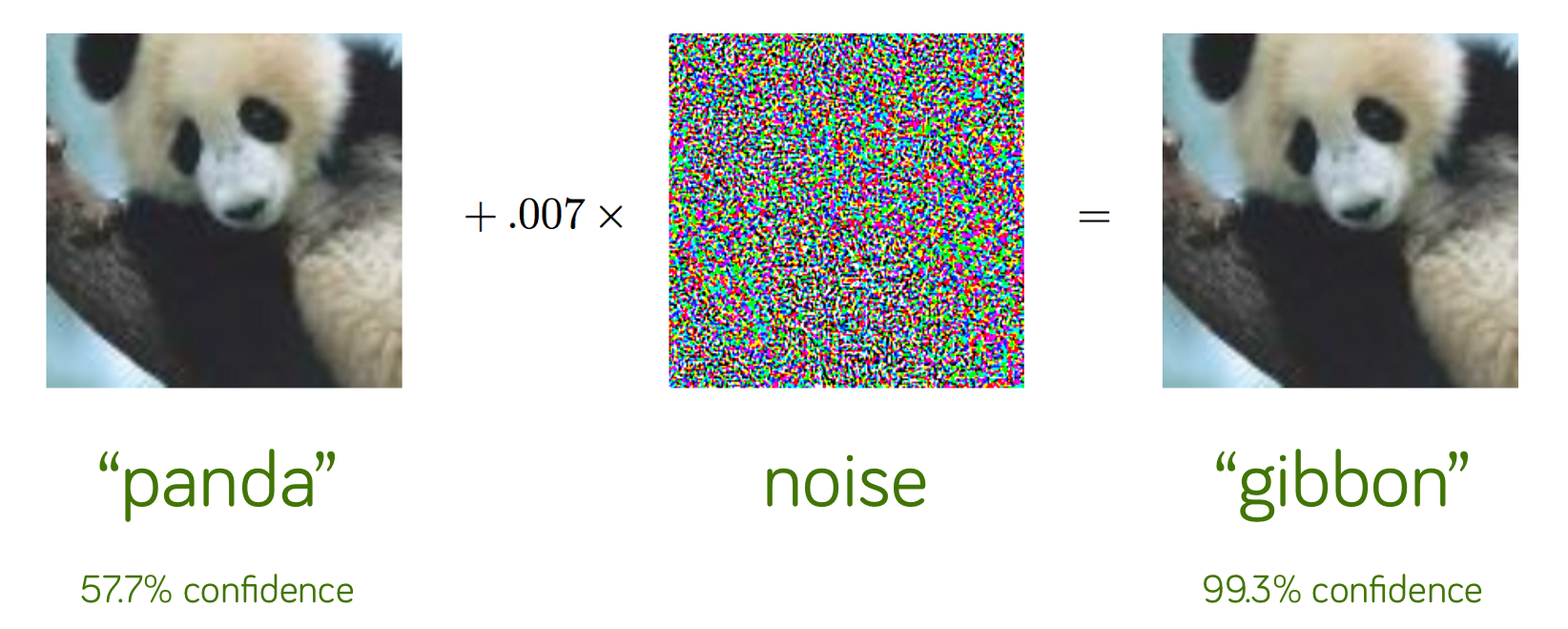
Adversarial attacks can change a panda into a gibbon.
Source : Explaining and Harnessing Adversarial Examples , Goodfellow et al, ICLR 2015.
Adversarial attack can be defined as a process of generating adversarial examples to a given classifier, which are samples that are misclassified by the model but are only slightly different from correctly classified samples drawn from the data distribution 2. Projected Gradient Descent 3 (PGD) is a popular attack method that iteratively generates adversarial examples as the following:
where
Adversarial attacks can be performed under various scenarios, i.e., within different levels of access to the target classifier. In the white-box setting, the adversary has full access to the classifier except test-time randomness 7. Whereas in the black-box setting, the adversary has no information about the classifier nor the data used for training the model.
Adversarial defense is a method used during training or inference in order to alleviate the damage from the potential adversarial examples. Training the model explicitly against some of the well-known attack methods is one of the easiest and robust defense methods 2.
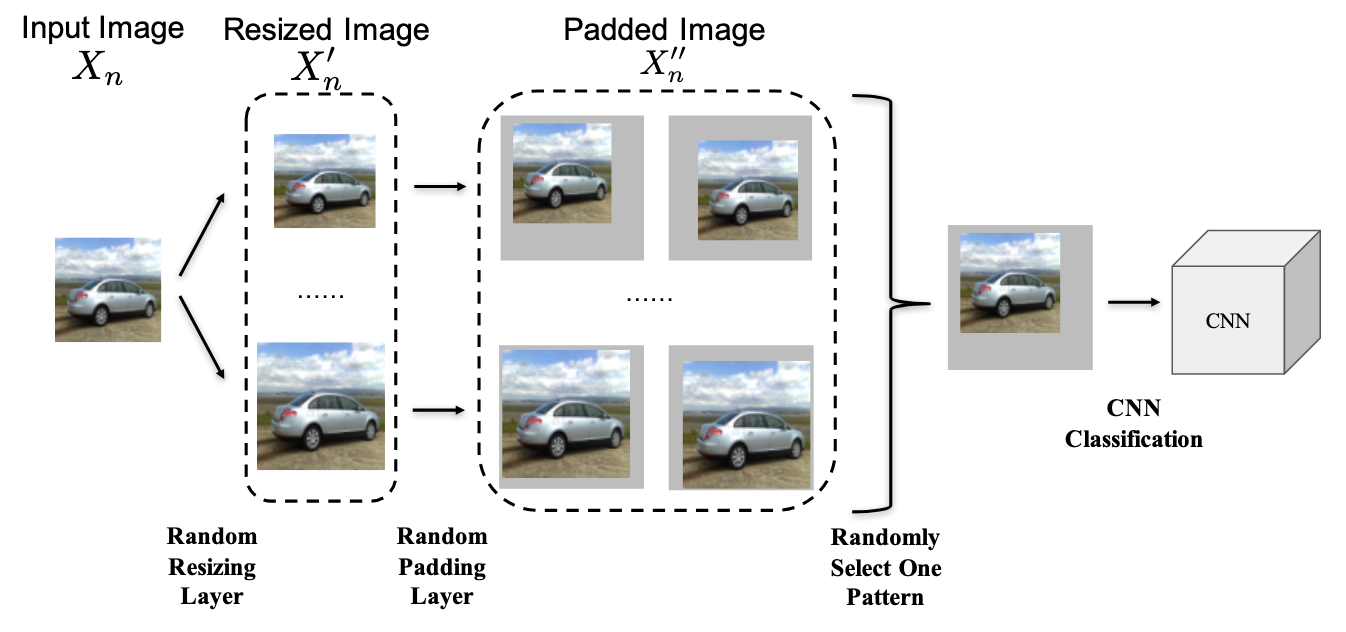
Adversarial defense by random resizing and padding of image.
Source: Mitigating Adversarial Effects Through Randomization, Xie et al, ICLR 2018.
Many defense methods exploit domain-specific invariance within the dataset. In the field of computer vision, random resizing and padding of the input image can be a method of defense 8 since the classified label must remain the same regardless of its size. Swapping a small number of pixels or using wavelet-based approximations can act as another method 9.
2. Measuring Pixel Robustness
Robustness of a classifier can be measured differently according to the distance metric and the attack method used for evaluation 10. However, most of the adversarial attacks solve an optimization problem related to the original loss function of the classifier to generate an example 2,3,10,11,12. Thus the solution of the problem depends highly on the direction and magnitude of the gradient of the input features.
Experiments on the ImageNet dataset show that the gradients from the input data not only depend on each of the images, but also on the structure of the classifier itself. In order to remove the effect from the individual images, one can compute the mean absolute value of the input gradient for each image pixel, with respect to all images in the dataset:
where
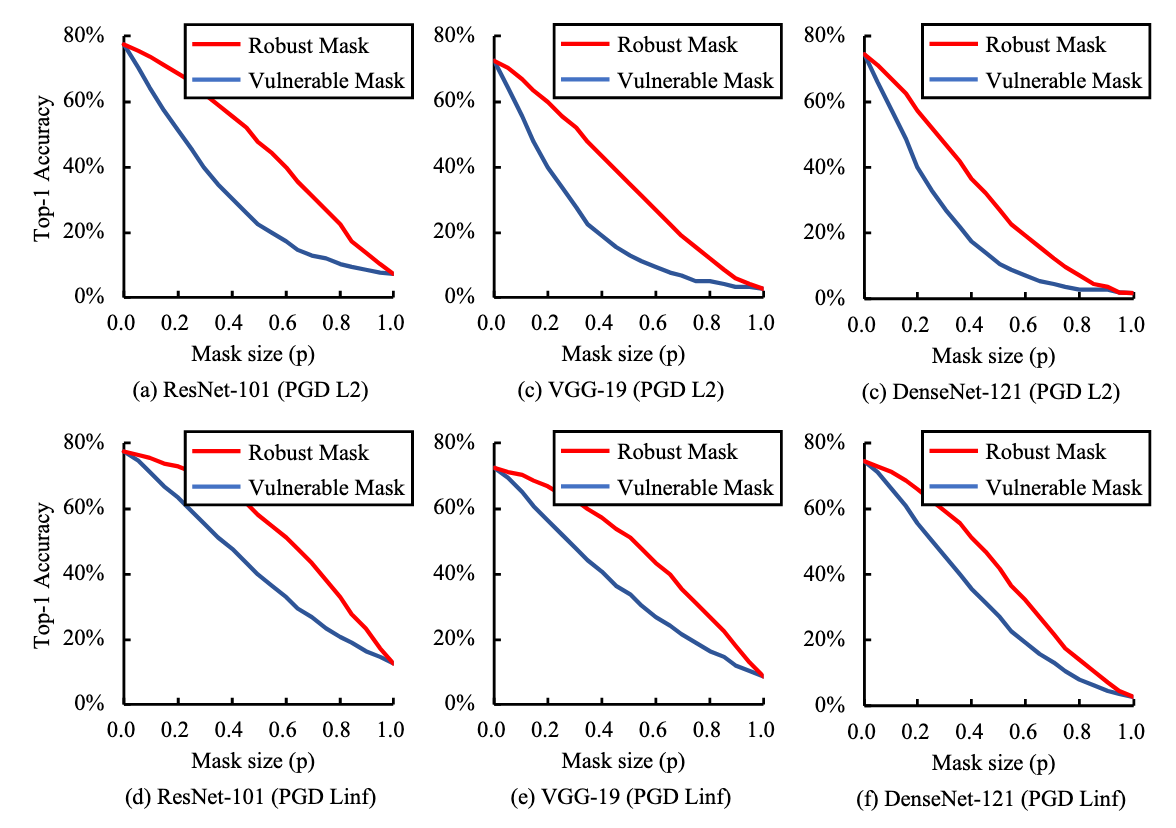
Top-1 accuracy on ImageNet validation dataset after masked PGD attacks.
Source: Where to be Adversarial Perturbations Added? Investigating and Manipulating Pixel Robustness using Input Gradients, Hwang et al, ICLR DebugML Workshop 2019.
To illustrate the relationship between
The above figure shows the average top-1 classification accuracy on ImageNet validation dataset for the combined input
3. Pixel Robustness Manipulator
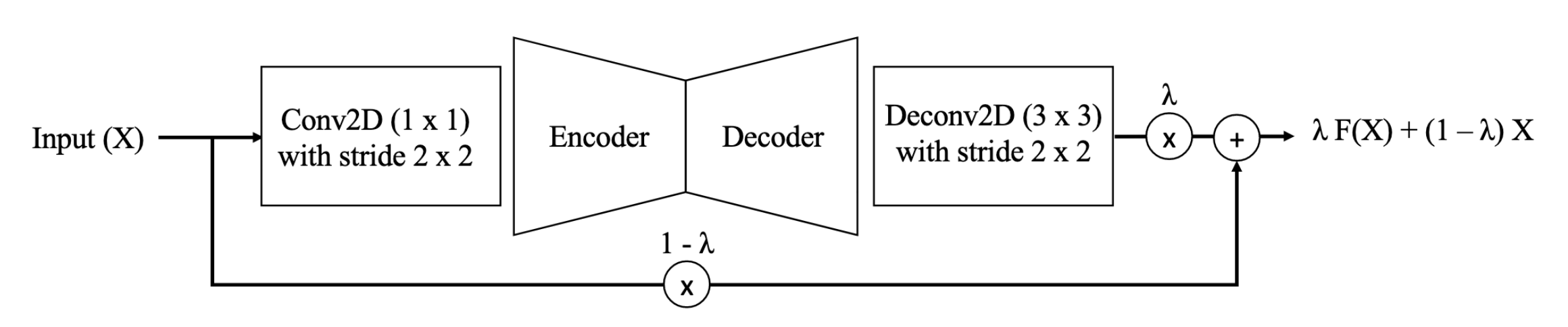
Overview of a PRM module. The first convolutional layer can be replaced with any convolutional filter with sparse connections.
Source: Same as above.
Now if one can control the distribution of
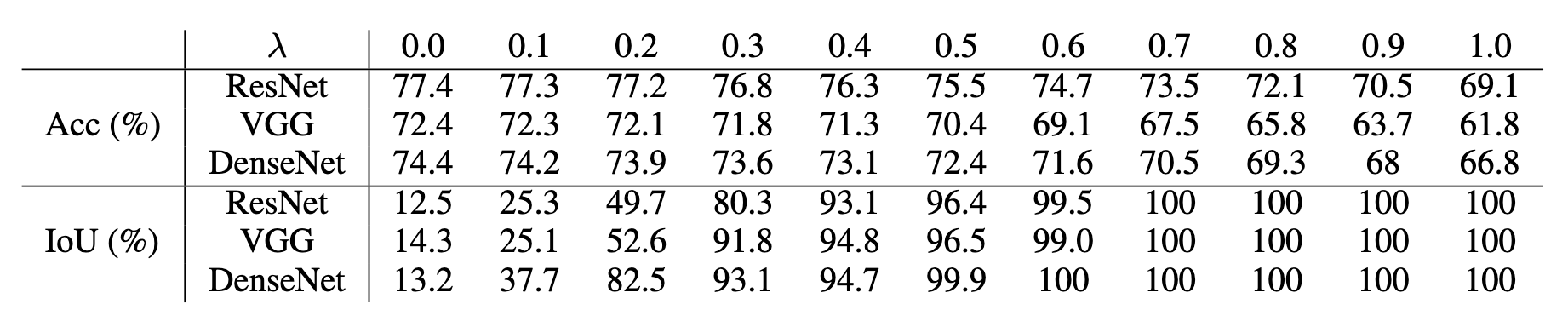
Top-1 accuracy on ImageNet validation dataset (Acc) and Intersection over Union (IoU) with the designated pixels for various values of λ using the PRM module.
Source: Same as above.
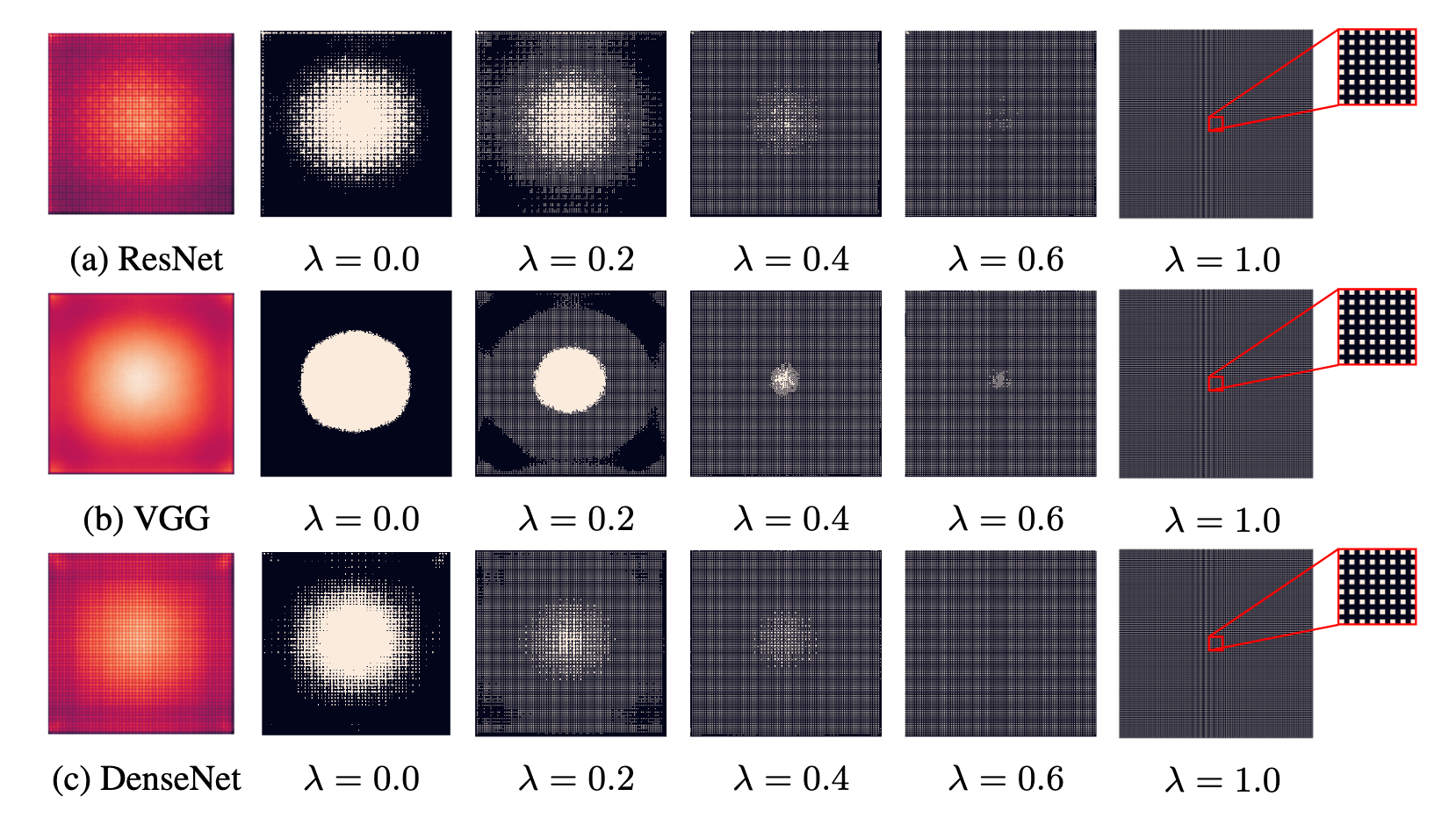
Heatmaps of the average input gradient for various values of λ using the PRM module.
Source: Same as above.
The above results were obtained from experiments on the ImageNet dataset using the PRM module depicted above. Since the PRM module is connected to approximately 25% of the input image pixels, the Intersection over Union (IoU) was calculated between the top 25% percentage of
Then if one can stochastically change the distribution of
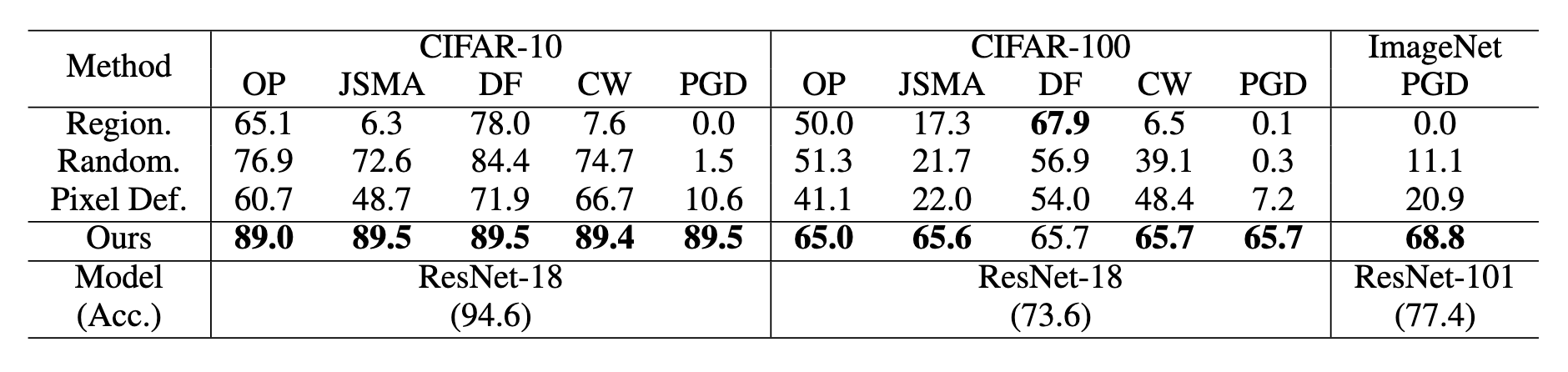
Top-1 accuracy (%) of 4 defense methods against 5 attack methods on CIFAR-10, CIFAR-100, and ImageNet validation datasets. The number below the name of the classifier stands for the top-1 accuracy without adversarial attacks.
Source: Same as above.
5 different adversarial attack methods were performed for evaluation: One Pixel attack (OP)13, JSMA 11, DeepFool (DF) 12, Carlini & Wagner (CW) 10, and PGD. Region-based defense 14, Randomization 8, and Pixel Deflection 9 were used for benchmarks in adversarial defense. "Ours" stands for the defense strategy using the same pretrained PRM module shown above
4. Summary
Recent progress on the field of adversarial attacks show that many contemporary deep learning models are vulnerable to imperceptible perturbations. However, most of the defense methods are either resource-heavy or domain-specific. Although this paper also has empirical support limited to the image domain, analyzing and manipulating the robustness of model by using input gradients is a method that can be easily utilized in a lot of different domains as well. Further research on methods for modifying the gradients during inference may provide defense strategies which also work in full white-box scenarios.
Reference
[1]
Where to be Adversarial Perturbations Added? Investigating and Manipulating Pixel Robustness using Input Gradients, Hwang et al, ICLR DebugML Workshop 2019.
[2]
Explaining and harnessing adversarial examples, Goodfellow et al, ICLR 2015.
[3]
Towards deep learning models resistant to adversarial attacks, Madry et al, ICLR 2018.
[4]
Adversarial examples in the physical world, Kurakin et al, ICLR 2017.
[5]
Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition, Sharif et al, CCS 2016.
[6]
Robust Physical-World Attacks on Machine Learning Models, Eykholt et al, CVPR 2018.
[7]
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples, Athalye et al, ICML 2018.
[8]
Mitigating Adversarial Effects Through Randomization, Xie et al, ICLR 2018.
[9]
Deflecting Adversarial Attacks with Pixel Deflection, Prakash et al, CVPR 2018.
[10]
Towards Evaluating the Robustness of Neural Networks, Carlini et al, IEEE 2017.
[11]
The limitations of deep learning in adversarial settings, Papernot et al, IEEE 2016.
[12]
Deepfool: a simple and accurate method to fool deep neural networks, Moosavi-Dezfooli et al, CVPR 2016.
[13]
One pixel attack for fooling deep neural networks, Su et al, arXiv preprint 2017.
[14]
Mitigating evasion attacks to deep neural networks via region-based classification, Cao et al, ACM 2017.






