1. 들어가며
지난 10월 28일부터 이틀간 미국 산타클라라에서 열린 2025 US LLVM Developers’ Meeting에 ML2의 엄의섭님께서 발표를 진행하게 되었습니다. 앞서 6월에 개최된 AsiaLLVM 2025에 이어, ML2의 박찬연, 이진명, 엄의섭님이 이번 2025 US LLVM Developers’ Meeting에 참석했습니다. 또한 비슷한 기간에 Pytorch Coference 2025가 인근 샌프란시스코에서 개최되어 함께 참석할 수 있었습니다.

본 포스팅에서는 먼저 LLVM Developers’ Meeting에서 진행된 엄의섭 님의 발표를 중심으로 IREE의 성능 분석 및 최적화 여정을 정리하고, 이어서 IREE 메인테이너와의 대화를 통해 살펴본 컴파일러 최적화에 대한 관점과 MLIR의 역할, 그리고 인상 깊었던 주요 발표들을 통해 본 오픈소스 컴파일러 툴체인의 발전 방향을 함께 소개하고자 합니다. 이후 PyTorchCon 2025에서 확인한 PyTorch 생태계의 확장 방향과 주요 프로젝트들을 정리하며, 특히 컴파일러, 추론, 엣지 배포라는 키워드를 중심으로 두 행사에서 느낀 공통된 흐름을 함께 살펴보려 합니다.
2. LLVM Developers' Meeting 발표
의섭님께서 이번 2025 US LLVM Developers’ Meeting에서 발표하게 된 주제는 “Optimizing IREE to Match Llama.cpp: An Introduction to IREE Optimization for newbies through benchmark journey” 이었습니다.

IREE는 multi-frontend로부터 multi-backend 컴파일링을 지원하는 통합 ML 컴파일러 프레임워크로서, pytorch, onnx, jax 와 같은 ML 프레임워크로 작성된 학습 및 추론 코드를 NVIDIA, AMD 가속기에서 돌아갈 수 있도록 lowering 을 제공합니다.
이번 발표에서 의섭님께서 다뤄주셨던 내용은 IREE 라는 MLIR 기반의 통합 컴파일러가 실제 LLM 워크로드 위에서 성능이 어떻게 작동하는지를 확인하고자 하는 시도에 관한 것이었습니다. 원래 Llama3 모델을 테스트 하려고 했었으나, 실험 속도를 높이기 위해서 TinyLlama 를 사용하였습니다. IREE의 성능과 llama.cpp 성능간의 차이는 예상보다 꽤 컸습니다. 전자는 23000 ms/token, 후자는 84 ms/token 로 약 200 배 이상의 성능차이를 보였습니다.
이 정도 차이는 병목이 어디인지부터 다시 봐야 하는 수준이라 이후의 벤치마크/프로파일링 여정을 설득력 있게 이어나갈 수 있었습니다. 우선 IREE 실행에서 토큰당 지연이 커, 정확히 어디서 시간 지연이 발생하는지를 확인하기 위한 프로파일링을 진행하였습니다.
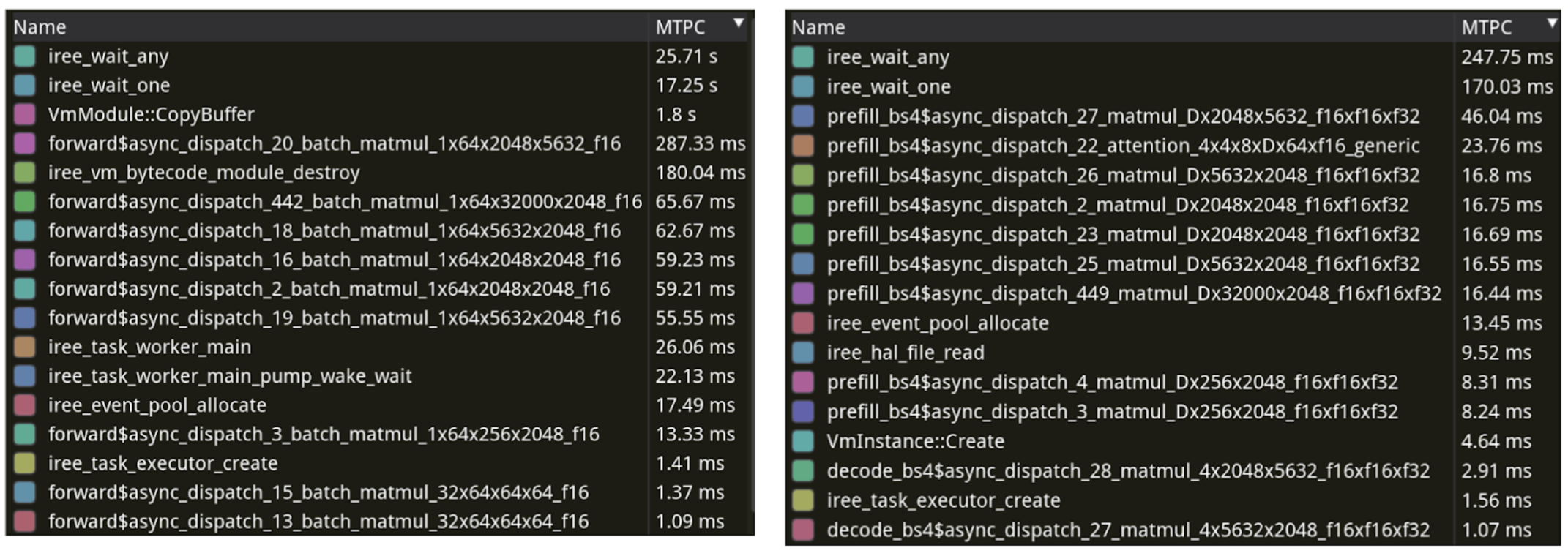
프로파일링을 위해 tracy 를 사용하였으며, 이를 통해 각 프레임 별로 소요된 시간을 측정할 수 있었습니다. 실제 프로파일링 결과를 보면 iree 관련 스레드 중 iree_wait_* 의 실행이 가장 오래 걸렸다는 것을 확인할 수 있습니다. 즉 실제 연산보다, 무언가를 기다리느라 시간이 오래걸리는 상황이었습니다.
이러한 결과에 대한 설명으로는 LLM의 추론 구조를 떠올려 보는 것이 도움이 되었습니다. LLM은 decode 하는 단계에서 필연적으로 autoregressive 한 구조를 갖기 때문에 토큰을 한 개씩 생성하고, 매 스텝마다 과거 토큰의 Key와 Value를 KV cache에서 다시 읽습니다. 컨텍스트가 길어질 수록 읽어야 하는 Key와 Value가 늘기 때문에, 연산량(FLOPs) 보다 메모리 트래픽이 먼저 병목이 되는 경우가 많습니다. 그래서 wait 하는 시간이 길게 잡힌다는 건 “연산 최적화 부족”이라기보다, 비동기 실행이 메모리 병목으로 인해 지연되는 상황이었습니다.
실제로 추론 코드에 paged attention을 구현한 후에는 23000 ms/tok 였던 추론 속도가 421 ms/tok 으로 줄어드는 것(55배 성능 개선)을 확인할 수 있었습니다. 이는 -O0, -O1, -O2 의 옵션을 비롯한 그 어떤 MLIR 최적화 보다도 더 높은 성능을 내는 최적화였습니다.
단순 벤치마크의 비교 외에도 MLIR 코드 디버깅에 필요한 정보들 또한 발표에서 함께 공유하였습니다. 특히, 중간 표현 단계에 있는 MLIR들은 보통 하나의 파일에 사이즈가 지나치게 커지는 문제가 있었습니다. 모델 파라미터들이 MLIR에 함께 포함되는 경우에는 특히 파일 사이즈가 4GB 를 넘어서 디버깅을 위해서 파일을 열어보는 것조차 쉽지 않았습니다. 이는 Flow dialect에서 제공해주는 NamedParameter Attribute, 또는 그와 유사한 기능을 하는 컴포넌트를 직접 구현해 사용하면 해결할 수 있었습니다.
발표 이후 포스터 발표도 함께하게 되었는데요, 많은 분들이 관심을 가져주셨습니다. Quick talk은 발표 시간이 제한적이라 충분한 전달을 하기가 어려울 수 있는데요. 포스터 세션은 이를 보완할 수 있는 좋은 기회로 사용할 수 있었습니다.

Caption: Asia LLVM 에서도 만났던 크리스 래트너와의 대화
3. IREE 메인테이너와의 대화
포스터 세션을 진행하면서 IREE 프로젝트의 주요 메인테이너 중 한명인 Scott과 대화할 수 있는 시간을 가졌습니다. 덕분에 IREE 프로젝트의 히스토리와 비하인드 스토리를 들어볼 수 있게 되었는데요. 원래 IREE 프로젝트는 Vulkan을 주요 타깃으로 개발되었다고 합니다. Vulkan 은 게임/그래픽스에서 주로 사용되던 API로 유명하지만, SPIR-V 기반의 범용 컴퓨팅도 지원해서 이식성 높은 GPU 백엔드를 만들 때 첫 구현 타깃으로 사용되곤 했습니다. AMD에 인수된 이후 ROCm 백엔드에 대한 지원이 추가되었고, 또 중점적으로 개발되는 중이라고 합니다.
대화 중 특히 인상 깊었던 부분은, “성능 최적화”를 이야기할 때 우리가 흔히 떠올리는 lowering 단계의 최적화가 언제나 가장 효과적인 수단은 아니라는 점이었습니다. 이번에 의섭님께서 진행한 벤치마크 결과와 같이 각 Dialect 간의 lowering 단계에서의 최적화보다도, 추론 코드 레벨에서의 최적화가 더 유의미한 결과를 낼 때가 더러 있다고 하며, 실제 추론 코드 레벨에서의 최적화 (dispatch 구성, 동기화/이벤트에 대한 직접적 처리, 메모리 접근 패턴)가 더 큰 성능 차이를 만들어 낼 수 있다고 합니다.
IREE 메인테이너와의 대화에서 다음과 같은 생각이 들었습니다. MLIR은 그 유연성으로 덕분에 다양한 요구사항에 맞게 적절한(good enough)한 하지만 최고의 성능은 아닌 컴파일러를 만드는데 적합한 도구인가 하는 생각이 들었습니다. LLVM 컴파일러 툴체인은 LLVM IR이라는 고정된 중간표현을 두고, frontend와 backend를 둬서 modularity를 확보했고 이는 LLVM 프로젝트 성공의 기반이 되었습니다. MLIR은 과거 성공을 가져다줬던 고정된 LLVM IR이 더이상 발전된 언어 환경과 도메인 환경을 담아내기는 어렵다는 점을 인정하면서 탄생하였습니다(이는 Asia LLVM에서 만났던 크리스 래트너에게 직접 들었던 이야기였습니다). 확장성과 유연성을 확보하는 것이 목적이었던 것 만큼. MLIR을 이용한 컴파일러는 최적화 보다도 그 확장성을 이용한 유연한 도메인 지원을 목표로 하는 것이 적합하지 않나 라는 생각도 들었습니다. (물론 컴파일러 세계에서는 2% 의 성능 개선 조차도 매우 유효합니다)
결국 최적화 문제를 풀 때는, 먼저 병목을 정확히 확인하고 그 병목을 만드는 요인을 우선적으로 제거하는 것이 가장 중요하다는 점을 다시 한 번 확인했습니다. 다음 단계로는, 어느 구간에서 lowering 최적화가 실제 성능 이득으로 이어지는지를 확인해보는 작업도 충분히 의미 있는 프로젝트가 될 것 같습니다.
4. 2025 US LLVM Developers’ Meeting 발표 하이라이트: 오픈소스 툴체인의 발전과정과 ML 통합 시도
4.1. ClangIR: Upstreaming an Incubator Project
ClangIR은 LLVM 컴파일러 툴체인의 C/C++ 컴파일러인 Clang을 MLIR로 다시 작성하는 프로젝트입니다. 이 프로젝트를 통해 LLVM 프로젝트 내에서 upstream(llvm-project) 과 downstream(incubating 중인 하위 프로젝트) 간에 어떻게 상호작용하는지, 그리고 새로운 기능 또는 컴포넌트가 어떤 과정을 거쳐 실제로 LLVM 생태계에 포함⋅배포되는지를 구체적인 사례로 보여주는 프로젝트였습니다.
오픈소스 프로젝트에서 downstream 에서 작성된 코드를 upstream으로 배포하는 것은 생각보다 쉬운 일이 아닙니다. Upstream과 downstream 사이에는 코드 차이가 계속 생기고, 양쪽 모두 빠르게 변하다 보니 end-to-end로 동작하는 기능을 안정적으로 맞추는 일이 쉽지 않습니다. 심지어 downstream에서 열심히 만든 변경이 여러 이유로 upstream에 받아들여지지 않는 경우도 있다고 합니다.
그럼에도 upstream에 올라가면 CI, clang-format 같은 인프라의 이점을 바로 누릴 수 있다는 점은 분명한 장점이라고 합니다. 인상적이었던 에피소드로, ClangIR이 처음 upstream에 배포되었을 때 “Hello world” 예제조차 컴파일되지 않았고, 이를 해결하기 위해 빠르게 코드를 추가로 shipping했다고 합니다. 발표자가 말한 “There are always moving pieces”라는 문장이 대규모 오픈소스의 현실을 잘 요약해주는 느낌이었습니다. LLVM 프로젝트에서 기여할 부분을 찾는 엔지니어라면 ClangIR을 살펴보는 것도 좋을 것 같습니다.
4.2. From proprietary to fully open-source: Arm Toolchain's adoption of LLVM technology
대규모 오픈소스 개발 프로세스의 역사를 통째로 들어볼 수 있는 기회는 생각보다 흔하지 않습니다. 이번 LLVM 개발자 미팅에서는 ARM 의 컴파일러 툴체인이 배타적 전용 (proprietary) 툴체인에서 오픈소스 LLVM 기반 툴체인으로 전환한 15년 간의 과정을 꽤 진솔하게 이야기 해주는 세션이 있었습니다. 과거 Arm 의 proprietary 컴파일러(armcc)는 임베디드 영역에서는 의미가 있었지만, 리눅스와 같은 보다 넓은 생태계를 지원하기에는 제약이 컸고, 그 사이 gcc(GNU compiler collection)은 더더욱 강력해지고 있었습니다. 오픈소스 대안을 찾던 Arm 입장에서는 라이선스(GPL) 또한 중요한 제약이었고, 여러 배경에 의해 2009년부터 LLVM에 관심을 갖게 됩니다. 당시에는 LLVM의 컴포저블(composable)한 구조가 매우 매력적이었지만, 당장 Arm 을 지원하는 생태계가 LLVM 내에 갖춰질 수 있는 상황이 아니었고, 컴파일러 툴체인의 백엔드 컴포넌트의 성숙도 또한 완전하지 않았기 때문에 고민이 되는 상황이었다고 합니다. 이 때문에 한동안은 LLVM 컴파일러 툴체인에서 프론트엔드와 중간단계(최적화를 포함한)를 사용하고 코드생성은 기존에 사용하던 armcc를 연결하여 사용하는 하이브리드 방식을 시도 했다고 합니다.
결국 2014년에는 Arm Compiler 5(armcc)에서 Arm Compiler 6(armclang, LLVM 기반)로 전환이 있었고, 이 과정에서 “커뮤니티는 생각보다 더 빠르게 움직이므로 upstream과 최대한 코드 상태를 유사하게 유지해야 유지보수 비용이 줄어든다” 는 교훈을 얻었다고 합니다. 특히 임베디드 툴체인은 모두 clang을 쓰면서도 코드사이즈 또는 확장 기능 때문에 이미 있는 코드를 다시 작성해야하는 경우가 많았고(reinventing the wheel) 이 때문에 표준화와 upstream에 코드를 올리는 것이 쉽지 않은 상황이 반복되었다고 합니다. 이런 파편화를 줄이기 위해 2022년부터는 “LLVM Embedded Toolchain for ARM” 그리고 나아가 llvm-project 만으로 구성된 완전한 임베디드 툴체인을 만드는 방향을 제시했습니다. 코드 사이즈나 일부 최적화에서 손해를 감수하더라도, 고객 입장에서는 “새 플랫폼에 오픈소스 소프트웨어를 더 직접적으로 얹을 수 있다”는 점이 인상적이었습니다. 로보틱스를 비롯한 엣지 디바이스에서는 Arm이 자주 사용되는 만큼, 이런 방향성이 저전력·임베디드 생태계 전반의 개발 속도와 이식성(portability)을 끌어올리는 계기가 되기를 기대합니다.
4.3. ML 과 컴파일러의 결합
그 외에도 이번 2025 US LLVM Developers’ Meeting에서는 ML을 컴파일러에 직접 얹으려는 시도도 여럿 소개되었습니다. Magellan(AlphaEvolve) 발표가 대표적이었는데, LLM 기반 에이전트를 이용하여 컴파일러의 최적화 정책(heuristic policy)을 생성하고, 실제 LLVM 툴체인 내의 프로젝트를 빌드해 벤치마크를 돌린 뒤 그 결과를 다시 피드백으로 받아 자동으로 정책을 개선하는 루프를 보여줬습니다. 특히 function inlining 같은 최적화를 사람 손으로 튜닝하지 않고도, 짧은 기간의 반복만으로 기존 upstream 휴리스틱 대비 의미 있는 개선을 만들 수 있었다는 점이 인상적이었습니다.
또다른IR2Vec 발표에서는 “중간표현(IR)으로 작성된 프로그램을 어떻게 머신러닝 모델의 입력으로 표현할 것인가”라는 문제를 다뤘습니다. 사람이 설계한 feature 대신 LLVM IR을 임베딩으로 변환해 MLGO(ML-guided optimization)에서 활용하는 접근인데, 후자를 TransE 라는 그래프구조 전용 모델의 인풋으로 활용하여 codesize를 줄이는 데 있어서 5% 이상의 개선을 보였습니다.
컴파일러 분야는 정합성(correctness)이 핵심이라, 결과가 확률적으로 변할 수 있는(stochastic) 접근이 상대적으로 보수적으로 도입되어 온 분야라고 느꼈습니다. 다만 최근에는 LLM의 성능이 빠르게 좋아지고, 실행⋅평가⋅피드백을 반복하는 에이전트형 워크플로우가 현실화되면서, “불확실한 생성”을 그대로 쓰기 보다는 측정가능한 벤치마크 루프 안에서 검증하며 활용하는 방식으로 점차 흡수되는 흐름이 보였습니다. 이번 발표들은 그 변화를 보여주는 사례였고, 앞으로 컴파일러 개발의 생산성과 탐색 속도를 끌어올리는 도구로서 LLM 기반 접근이 더 폭넓게 자리잡을 가능성이 있어 보였습니다. 아직은 function inlining 같은 간단한 최적화에 대해서 실험이되고 있지만 추후 보다 다양한 휴리스틱 최적화에 대해서도 실험들이 이어질 것으로 기대합니다.
5. PytorchCon 2025

PyTorch Developer Day로 시작해 2022년 처음 개최된 PyTorch Conference(PyTorchCon)는 이제 PyTorch 생태계 전반을 조망하는 대표적인 행사로 자리 잡았습니다.
특히 올해는 PyTorch 9주년이 되는 해이자, PyTorch Foundation이 Linux Foundation 산하의 Umbrella Foundation으로 전환된 첫 해라는 점에서 상징적인 의미가 컸습니다. 딥러닝 컴파일러부터 대규모 분산 학습, 추론, 그리고 엣지 AI까지 PyTorch 생태계가 얼마나 넓어졌는지를 실감할 수 있는 자리였습니다.
기조연설과 기술 세션뿐 아니라, Birds of a Feather와 같은 커뮤니티 세션을 통해 참석자들이 자유롭게 의견을 나누는 모습도 인상적이었습니다.
PyTorchCon의 Keynote와 Talk들은 PyTorch 공식 YouTube 채널에서 확인하실 수 있습니다.
5.1. PyTorch의 방향성: “The Open Language of AI”
이번 PyTorchCon에서 주목할만한 점은 “PyTorch 생태계의 확장” 이었습니다.
PyTorch는 더 이상 단순한 딥러닝 프레임워크가 아니라, “The Open Language of AI”, 나아가 AI 시스템 전체를 관통하는 기반 언어이자 인프라가 되겠다는 비전을 명확히 제시하고 있었습니다. vLLM, DeepSpeed, Ray 등 이미 성공적으로 자리 잡은 오픈소스 프로젝트들이 PyTorch 생태계로 편입되었의며, 컴파일러/분산 학습/추론/서빙/엣지 배포까지 전 계층을 포괄하는 다양한 프로젝트들도 소개되었습니다.
PyTorch가 하드웨어 가속부터 에이전트 시스템 배포까지 아우르는 표준 언어가 되겠다는 비전을 제시한 만큼, 이번 기조연설과 주요 발표 전반에서는 몇 가지 핵심 키워드가 반복적으로 등장했습니다. 이번 PyTorchCon의 주요 키워드로는 ‘추론(Inference)’, ‘대규모 분산 학습(Large-scale Distributed Training)’, ‘컴파일러’, ‘엣지 및 로컬 배포’ 를 꼽을 수 있을 것 같습니다.
추론(Inference) 분야에서는 vLLM을 기반으로 한 서버 환경의 고성능 추론뿐만 아니라, ExecuTorch를 중심으로 엣지 및 로컬 환경에서의 추론을 강화하려는 움직임이 두드러졌습니다. 이를 위해 관련 API를 정비하고, 배포 도구를 통합하는 방향으로 생태계를 정리하고 있습니다.
대규모 분산 학습(Large-scale Distributed Training) 을 위한 신규 프로젝트들ㅡ소개되었습니다. Momarch, TorchComms와 같은 프로젝트는 다수의 GPU 클러스터를 활용하는 것은 물론, 장기적으로는 이기종(heterogeneous) 하드웨어 플랫폼까지 지원하는 것을 목표로 하고 있습니다. 이와 같은 추론 성능 향상을 뒷받침하기 위해 컴파일러 의 중요성도 다시 한번 강조되었습니다. PyTorch는 Triton과의 연동을 강화하고 있으며, vLLM이나 SGLang과 같은 추론 프레임워크와의 깊은 통합을 통해 전반적인 성능 개선을 도모하고 있습니다. 마지막으로 모바일 기기나 Ollama와 같은 로컬 LLM 프로젝트를 지원하기 위한 엣지 배포 전략의 일환으로, ExecuTorch 1.0이 공식 공개되었습니다. 포스터 세션에서도 ExecuTorch를 활용한 연구들이 많이 소개되었는데요, 다양한 로컬·엣지 환경으로 확장하려는 PyTorch의 방향성을 확인할 수 있었습니다.
5.2. 프로젝트 하이라이트: ExecuTorch 1.0, Helion
이중에서 특히 인상 깊었던 '컴파일러' '엣지 및 로컬 배포' 관련 두 가지 프로젝트를 간단히 소개합니다.
ExecuTorch 1.0 — PyTorch의 엣지/온디바이스 AI 배포 솔루션
ExecuTorch 1.0은 PyTorch 모델을 모바일, 임베디드, 데스크톱, IoT 같은 엣지 디바이스에 그대로 배포할 수 있는 end-to-end 솔루션입니다. 별도의 모델 변환(conversion)이나 코드 재작성 없이도 PyTorch 모델을 직접 배포할 수 있고, 다양한 하드웨어 백엔드(CPU, GPU, NPU, DSP 등) 를 지원합니다. 특히 경량화된 런타임을 제공해, 제한된 리소스 환경에서도 고성능 추론을 가능하게 합니다.
실행 과정은 크게 (1) PyTorch 모델을 그래프로 캡처하고, (2) 최적화 및 하드웨어 특화 컴파일을 거쳐 .pte 형식으로 변환하며, (3) 경량 런타임에서 실행하는 방식으로 구성됩니다. 이를 통해 클라우드에 의존하지 않는 빠른 응답, 개인정보 보호 강화, 인터넷 없이 작동하는 AI 기능을 엣지 환경에서도 제공할 수 있습니다.
Helion — 고성능 커널 개발을 위한 PyTorch 네이티브 DSL
Helion은 PyTorch 네이티브 DSL(Domain Specific Language) 로, 이기종 하드웨어 환경에서도 고성능 커널 작성을 획기적으로 단순화하는 것을 목표로 합니다. Helion이 제시하는 핵심 개념은 공식 문서에서 “PyTorch with tiles” 라는 표현으로 요약됩니다. 여기서 tiles란 GPU에서 고성능 연산을 달성하기 위해 연산을 작은 블록 단위로 분해해 실행하는 타일링(tile-based) 계산 모델을 의미합니다. 기존에는 이러한 타일링을 직접 설계하기 위해 CUDA나 Triton 코드에서 복잡한 인덱싱, 블록 크기 설정, 메모리 배치 등을 수작업으로 구현해야 했지만, Helion은 이 과정을 고수준 추상화로 끌어올립니다.
개발자는 익숙한 PyTorch 스타일의 코드로 연산을 정의하면서, hl.tile과 같은 구문을 통해 “이 연산은 타일 단위로 실행되어야 한다”는 의도를 선언적으로 표현하기만 하면 됩니다. 이후 Helion은 해당 코드를 Triton 커널로 자동 컴파일하고, 내부 autotuner를 통해 타일 크기, 스레드 배치, 메모리 접근 패턴 등 수천 개의 후보 구현을 탐색해 하드웨어에 최적화된 실행 방식을 선택합니다.
이러한 접근 방식 덕분에 Helion은 다양한 GPU 아키텍처에 걸친 성능 이식성(performance portability)을 확보하는 동시에, 개발자가 저수준 커널 최적화에 매몰되지 않고 모델과 연산 로직 자체에 집중할 수 있도록 합니다. 결과적으로 Helion은 PyTorch의 높은 생산성과 타일 기반 GPU 프로그래밍의 성능적 이점을 결합한, PyTorch 컴파일러 스택의 중요한 진화 방향을 보여주는 프로젝트라고 볼 수 있을 것 같습니다.
5.3. 하드웨어와 가속기: 추론 시대의 인프라 전략
모델 서빙(inference)에 대한 수요가 급격히 증가하면서 GPU, AI 가속기, 그리고 데이터센터 설계에 대한 관심 역시 크게 높아지고 있습니다. 이러한 흐름 속에서 특히 인상 깊었던 세션은 Keynote Panel: Hardwares & Accelerators 이었습니다. 해당 패널 토론에서 반복적으로 강조된 키워드는 속도, 유연성, 그리고 AI 특화 운영 능력 이었습니다.
대규모 AI 학습과 추론에 특화된 신규 클라우드 인프라 ’Neo-Cloud’ 는 AWS, Azure, GCP와 같은 전통적인 하이퍼스케일러 클라우드와 여러 측면에서 뚜렷한 차이를 보입니다. 기존 클라우드는 CPU, 데이터베이스, 스토리지 중심의 워크로드에 최적화되어 강한 가상화와 중복 설계를 채택해 왔지만, 대규모 GPU 클러스터 환경에서는 이러한 접근이 오히려 비효율적일 수 있다는 지적이 이어졌습니다.
AI 워크로드에서는 저지연·고대역폭 네트워크와 함께, 오류상황을 자연스러운 전제로 받아들이는 결함 허용(fault-tolerant) 운영 방식이 훨씬 중요합니다. 특히 GPU는 CPU에 비해 고장이 잦은 하드웨어이기 때문에, “절대 실패하지 않는 인프라”보다는 빠른 오류 탐지, 격리, 그리고 복구가 가능한 구조가 핵심 경쟁력으로 강조되었습니다.
또한 컴퓨팅 자원이 희소해진 현 시점에서는, 비용 최적화보다 얼마나 빠르게 인프라를 구축하고 서비스를 오픈할 수 있는가가 더 중요한 차별점이 되고 있다고 분석했습니다. 늘어나는 모델 서빙 수요에 대응하기 위해, 인프라는 반드시 실패를 전제로 설계된 auto-recovery 철학을 가져야 한다는 점도 공통된 의견이었습니다.
6. 정리하며
2025 US LLVM Developers’ Meeting과 PyTorchCon 2025을 연달아 보고 나니, 요즘 AI 엔지니어링의 중심은 모델 자체뿐 아니라 모델을 둘러싼 실행 · 배포 · 운영의 시스템으로 빠르게 이동하고 있다는 인상이 강하게 남았습니다. 컴파일러 커뮤니티는 더 넓은 범위의 디바이스를 지원하기 위해 발 빠르게 확장해 나가고 있었고, 파이토치 커뮤니티 역시 제품화를 지원하기 위한 통합된 생태계를 만들기 위해 노력하고 있었습니다.
전반적인 소프트웨어 스택의 성숙도가 올라와서, 작은 팀도 표준 도구를 조합해 빠르게 실험하고, 병목을 찾고, 개선을 반복하는 방식으로 충분한 기술적 임팩트를 낼 수 있을 것 같습니다. ML2에서도 이번 기회를 통해 얻은 인사이트를 바탕으로, 저희가 다루는 여러 어플리케이션 및 연구에서의 병목을 개선해나가며 작게라도 upstream에 기여할 수 있도록 노력해보고자 합니다.







