
1. Introduction
This post is an introduction to a simple multi-agent reinforcement learning environment, ML2-MARL-ENV, that can be used to train multi-agent RL algorithms. It aims to explain the use cases of the environment to help future RL researchers in training a multi-agent RL. Another purpose of this blog is to share my personal experiences that I have come across in the development stage, which will hopefully help others better understand the nature of the project.
The API of the environment follows that of the convention of OpenAI gym environment.
2. Recent research and motivations
2.1 Backgrounds
Deep Reinforcement learning has brought significant progress in the field of multi-agent systems in recent years. Even after such achievements in this field, there exist only a few open source environments that can be used to train and test multi-agent reinforcement algorithms. Moreover, the environments available for multi-agent RL researches are usually real world applications or complex online games, which may lead to difficulties in training and testing the huge environments to replicate the works on the papers.
Eric Liang and Richard Liaw, Scaling Multi-Agent Reinforcement Learning, BAIR blog 6
To complement the situation, the environment introduced in this blog aims to provide a simple multi-agent environment that can be used to train and test RL algorithms in a more light-weighted and deterministic manner. Mainly, the games consist of grids that are smaller than 2d-array of size 100x100. The variables of each item in the array can be 0~255 of the RGB scale.
Also, as a response to "Requests for Research 2.0" by OpenAI team, Slitherin’ game, which is a multiplayer clone of the classic Snake game, was implemented in this environment library.
2.2 Motivations
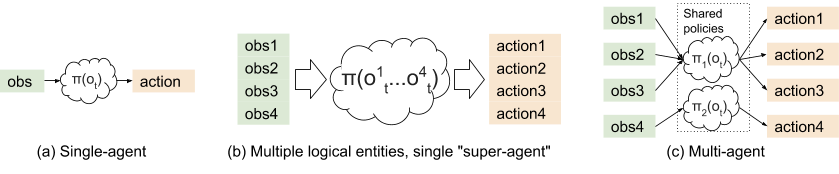
Many of the successful applications of Reinforcement algorithms have mainly been focused on single agent problems, where modeling or predicting the behavior of other agents have been mostly neglected. Even when a multi-agent environment is used, because of its nature of complexity, the models mostly use a single critic (central observer) that can observe the behaviors of many agents synchronously.
However, many works involving multi-agent RL have been proposed in the recent years. Since RL methods that are designed for single agents are typically poor on such multi-agent tasks, there is a strong demand for a new algorithm (or structure) that is specifically designed and modified for multi-agent RL.
In addition to the coordination of autonomous vehicles 9 or traditional distributed logistics, 10 which are naturally modelled as cooperative multi-agent systems, new types of multi-agent tasks are being explored.

The StarCraft Multi-Agent Challenge 11
As in Figure 1, studies such as (Foerster et al. 2017) 8 rely on complex online games that make use of large resources and computing power. Since real world problems are even more complex than such video games, it would be justifiable to use such experiments to test an RL algorithm because when it successfully produce a desirable outcome it would naturally have a wider domain of applications. On the other hand, the cost of training such algorithm is high. If the system is not well managed, it would take an unreasonable amount of time and cost to test such an environment.
The main purpose of ML2-MARL-ENV is to provide mini test cases that can be used as a warm-up before rolling up the sleeves for the real complex games, so that a user can gain enough confidence to apply a successful algorithm to other more extensive environments.
3. Multi-agent Snake Game Environment
The first mini-game that I have developed was the game of Snake. The game is fairly simple. Each player starts with a snake of short length and controls it to grow its length by eating the food that is on the map. When the snake's head hits the wall or body of any other snake, the game is over.
A Major part of the program was designed by Young Hoon Kim at ML2, and only a few changes were made to enable multi-agent learning.
4. Multi-agent Grid-World Environments
This section includes a brief introduction to Grid-World Environments. The mini-games consist of 2D grids of small size, where multiple agents can cooperate with or compete against each other. This task was largely motivated by ma-gym 5, a multi-agent gym environment that precedes this project.
4.1 GridExplore
This game is set in a Grid World Env where the grid starts off with white blank cells. The blank cells indicate that the cells have not been explored by any agent. When the game starts, agents are put in a randomly selected blank cell. Agents start to explore the grid by marking blank cells as 'explored' cells. When all the blank cells are explored, the game is finished. Agents get rewards from the number of cells they have explored. Initially, the exploration range is set to a distance of 1, which means it can only explore cells within its range of 1 horizontally, vertically, and diagonally.

4.2 GridPath
GridPath was motivated by traffic control problems, where multiple controllable systems (e.g., traffic lights, autonomous vehicles) work together to reduce highway congestion. 6 In this game, the four agents try to navigate through a narrow path in which only one agent can go through at a time. Multiple agents cannot share a single cell, and when agents try to move into the same cell, they are pushed back to their original position. This also resembles a sequential social dilemmas with MARL 12 in a way that the agents have to cooperate to reach a common goal or compete to hinder the opponents.

5. Training the environment
At every training stage, a custom CNN was used. The customized CNN can capture relatively smaller size of images from the grid.

5.1 Single Agent Training
To produce a trainable multi-agent environment, I wanted to be sure that the environment can run in a single agent mode. Therefore, as a first attempt to train the Snake Game, I reduced the size of the grid for a single player snake game.
DQN
%Test env="python_1p-v0"%
Observation Image: four 10x10 image consisting of
Position of Agent's head, body, food, and the wall
Action Space: five actions (Up, Down, Left, Right, Idle)
%Training Info%
Deep Q-learning Network
gamma : 0.99
learning_rate : 0.0001
buffer_size : 50,000
batch_size : 16
num_steps : 5,000,000
eps_min : 0.1
eps_decay_steps : 2,000,000

| Mean Score(100 games) | 13.16 |
| Max Score | 18 |
| Standard deviation | 3.79 |
Again with the GridExplore game, DQN was used to train/test the environment with a single agent.
%Test env="GridExplore-v0"%
Observation Image: four 10x10 image consisting of
Position of the agent, the explored and the unexplored cells, and the wall
Action Space: five actions (Up, Down, Left, Right, Idle)
%Training Info%
Deep Q-learning Network
gamma : 0.99
learning_rate : 0.0001
buffer_size : 50,000
batch_size : 16
num_steps : 5,000,000
| Mean Score(100 games) | 37.2 |
| Max Score | 41 |
| Standard deviation | 2.81 |

PPO2
Policy gradient methods for reinforcement learning was also experimented with the environment.
%Test env="python_1p-v0"%
%Training Info%
Proximal Policy Optimization
n_envs : 8
nminibatches : 16
gamma : 0.99
learning_rate : 0.00025
num_steps : 15,000,000
cliprange : 0.2
num_of_epoch : 4

| Mean Score(100 games) | 22.21 |
| Max Score | 29 |
| Standard deviation | 4.09 |
5.2 Multi-agent Training
Prior to training a multi-agent model, I wanted to test whether it would be useful to use an observation image that is relative to the position of the snake's head. In such setting, all the images from each of the snake agents could be used to feed one central critic(PPO2). Here, the number of food generated on the map is increased to 4.
.gif)
| Mean Score(100 games) | 49.30 |
| Max Score | 72 |
| Standard deviation | 9.80 |
After a successful training of the single agent model for the snake game environment, a multi-agent mode with multiple snake agents was tested. The training setting was based on a PPO2 model, where each agent's observation was used to feed a central agent, similar to running a parallel environment to explore a variety of different scenarios. Each agent's goal is to maximize its score while competing against one another.
%Test env="python_4p-v1"%
%Training Info%
Proximal Policy Optimization
n_envs : 8
nminibatches : 16
gamma : 0.99
learning_rate : 0.00025
num_steps : 15,000,000
cliprange : 0.2
num_of_epoch : 4

Remarks
Surprisingly, I could observe two special behaviors of the snake agents.
-
Snake agents tend to compete in the early stages of the game, which is different from what I assumed that competing and killing another snake would be an experience that each agent acquire after winning out the others.
-
As observed in the above figure, snake agents try to lock down another snake to the corner when it can do so. The Green Snake blocks the Blue Snake from getting out of the corner when the two snakes compete against each other.
Summary
The ML2-MARL-ENV project was an internship project that I produced during my internship period at ML2. Before joining ML2, I have only had a little exposure to reinforcement learning algorithms, and rarely in multi-agent settings. However, with a small effort I was able to train competitive MARL agents using PPO2 with a central critic and observe special behaviors of the agents after training the agents in the environment for a sufficient but not extensive amount of time.
Future enhancements of ML2-MARL-ENV can be made by any open source contributors who wish to make use of this library.
References
1
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments by Lowe R, Wu Y, Tamar A, et al. arXiv, 2017.
2
Deep Decentralized Multi-task Multi-Agent RL under Partial Observability by Omidshafiei S, Pazis J, Amato C, et al. arXiv, 2017.
3
Emergent complexity through multi-agent competition by Trapit Bansal, Jakub Pachocki, Szymon Sidor, Ilya Sutskever, Igor Mordatch, 2018.
4
Multiagent Cooperation and Competition with Deep Reinforcement Learning by Tampuu A, Matiisen T, Kodelja D, Kuzovkin I, Korjus K, Aru J, et al. 2017
5
6
Scaling Multi-Agent Reinforcement Learning (https://bair.berkeley.edu/blog/2018/12/12/rllib/)
7
Proximal Policy Optimization Algorithms, by John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov, 2017
8
Counterfactual multi-agent policy gradients by J. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson. arXiv preprint arXiv:1705.08926, 2017
9
An overview of recent progress in the study of distributed multi-agent coordination by Cao, Y.; Yu, W.; Ren, W.; and Chen, G. 2013.
10
Multi-agent framework for third party logistics in e-commerce by Ying, W., and Dayong, S. 2005.
11
Samvelyan, M. et al. The StarCraft multi-agent challenge. Intl Conf. Autonomous Agents and MultiAgent Systems 2186–2188 (2019).
12
Multi-agent Reinforcement Learning in Sequential Social Dilemmas by Leibo, J. Z., Zambaldi, V., Lanctot, M., Marecki, J., and Graepel, T. (2017)






