
1. Introduction
Recently, research on the geometric properties of value functions and attempts to apply these properties to various fields of Reinforcement Learning (RL) have been actively conducted. This post is an introduction to Value Function Geometry including an introduction of the paper "The Value Function Polytope in Reinforcement Learning" by Dadashi et al 1.
This post aims to explain the basic concepts of value function linear approximation and representation learning. Also, the paper 1 establishes the geometric shape of value function space in finite state-action Markov decision processes: a general polytope. By reimplementing the paper myself, I was able to check the surprising theorems and geometric properties. I have attached some results that I checked directly in the post.
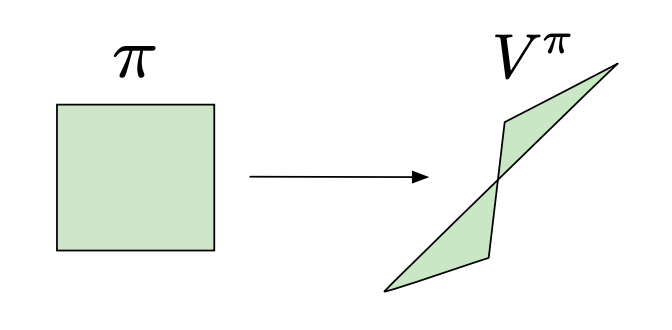
Figure 1: Mapping between policies and value functions 1
2. Background
We usually consider an environment with a Markov Decision Process(MDP) in Reinforcement Learning 2. Markov Decision Process
A stationary policy
State-value function
The return
The state-value function
Action-value function
The action-value function
In particular, the state-value function is an expectation over the action-value functions under a policy
In the case, we take an action by following an argmax policy
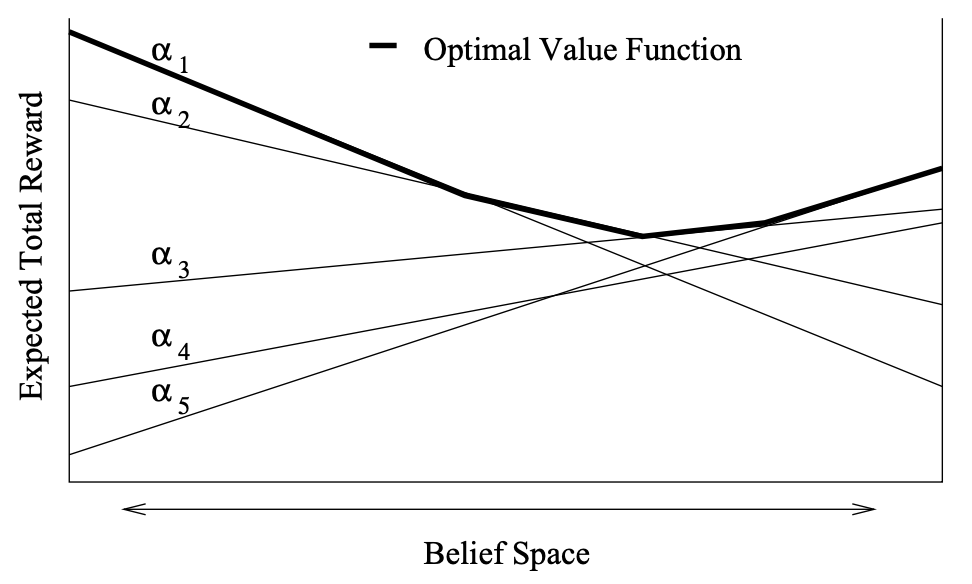
Figure 2: Geometric View of Value Function 3
Figure 2 represents the geometric relationship between the state-value function and the action-value function, when following an argmax policy. Each line corresponds to the action-value function and the bold line corresponds to the state-value function. It can be seen that the maximum action-value selected for each state is the state-value function. In Figure 2, it can also be checked that
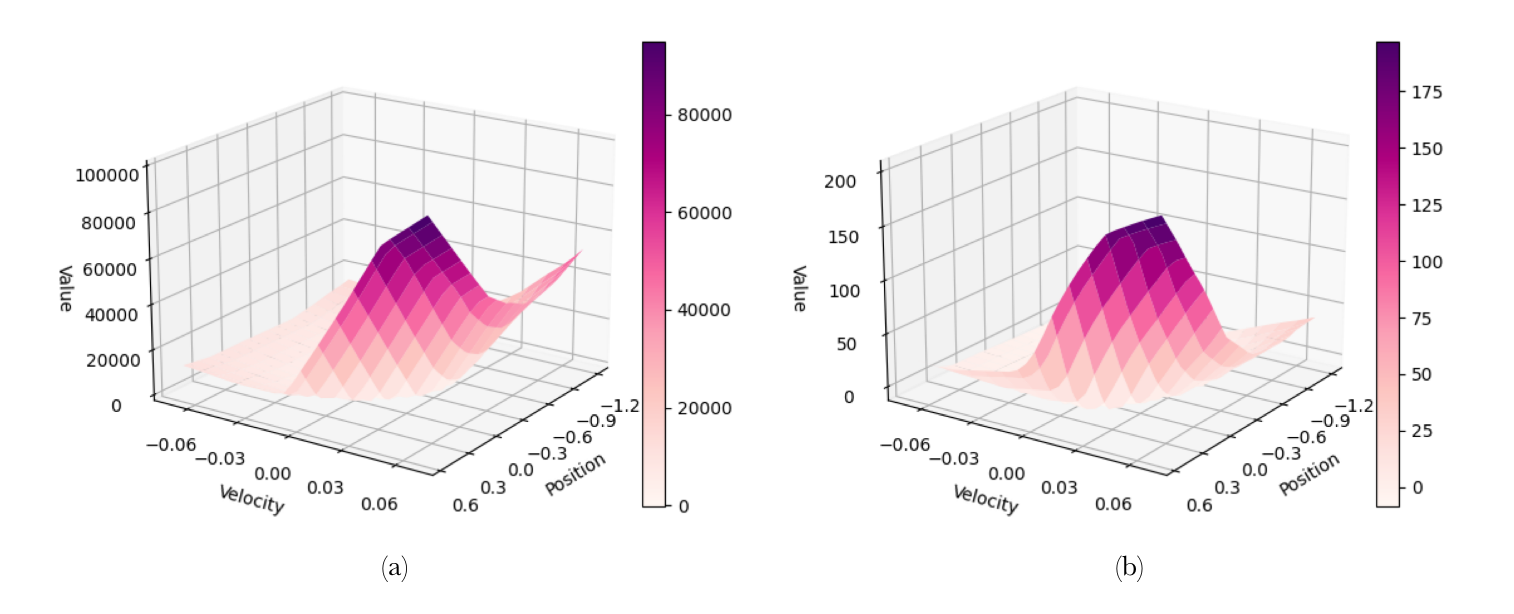
Figure 3: Value Functions for the mountain car problem using DQN
Figure 3 is an example of value functions that I obtained for the mountain car problem. Both used DQN (Deep Q-Networks) to train the agent. Figure 3(a) is based on 2000 runs of mountain car without changing the reward, and Figure 3(b) is based on 500 runs of mountain car with adding a heuristic reward. I gave a bonus reward of 15 times the velocity of the next state. By giving a heuristic reward to the agent, the mountain car was able to learn and train faster.
3. Value Function Linear Approximations
A value function for a policy
For a given representation
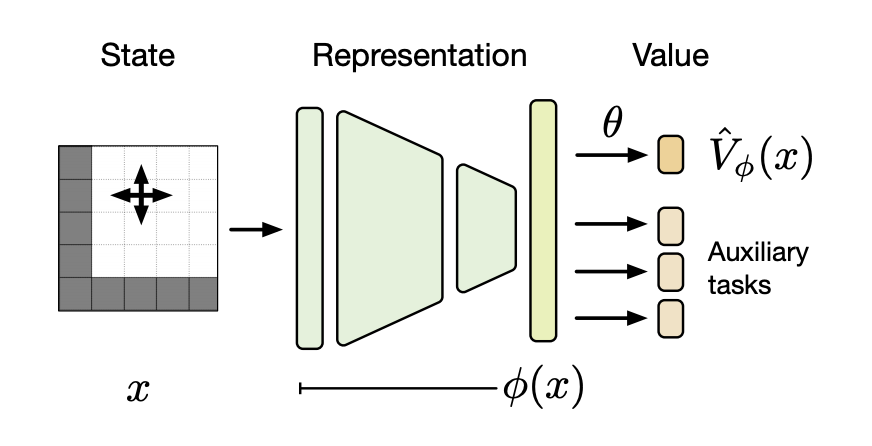
Figure 4: A deep reinforcement learning architecture viewed as a two-part approximation 4
Bellman operator
Assume a finite state space:
Let's start by introducing some vector and matrix notation to make it more convenient.
It is well known that the state-value function
Given a policy
Since
In the case, we do not know the entire model completely, we cannot calculate
Projection operator
Projection operator is a widely used operator in Statistics for Multiple Linear Regression Models and Least Squares Estimation.
For an
We let
Projector operator satifies the normal equations:
What if
Back to the value function approximation, let's assume a finite state space
We consider the approximation minimizing the squared error:
4. Value Function Polytope in Reinforcement Learning
Definition 1 : Polytope
We write
Definition 2 : Polyhedron
The Space of Value Functions
The main contribution of Dadashi et al 1 is the characterization of the space of value functions. The space of value functions is the set of all value functions obtained from all possible policies.
Dadashi et al 1 show that
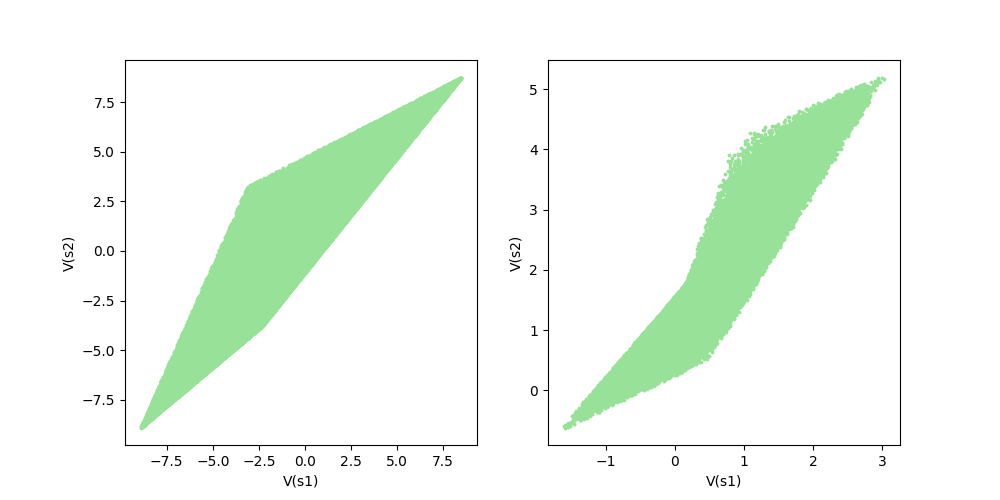
Figure 5: Space of Value Functions for 2-state MDPs
Figure 5 depicts the value function space
Figure 5: Left
Figure 5: Right
I used the following convention to express
To easily check the shape of the polytope, I checked with the value function spaces from 2-state MDPs, which is convenient to visualize. The policy space
In fact, if you look closely at the right of Figure 5, you'll find something a little odd. You may think it's not a perfect polytope because the upper left hand is a little empty. To double-check if the policy was sampled uniformly from the policy space, I visualized the mapping between policy samples and value function samples.
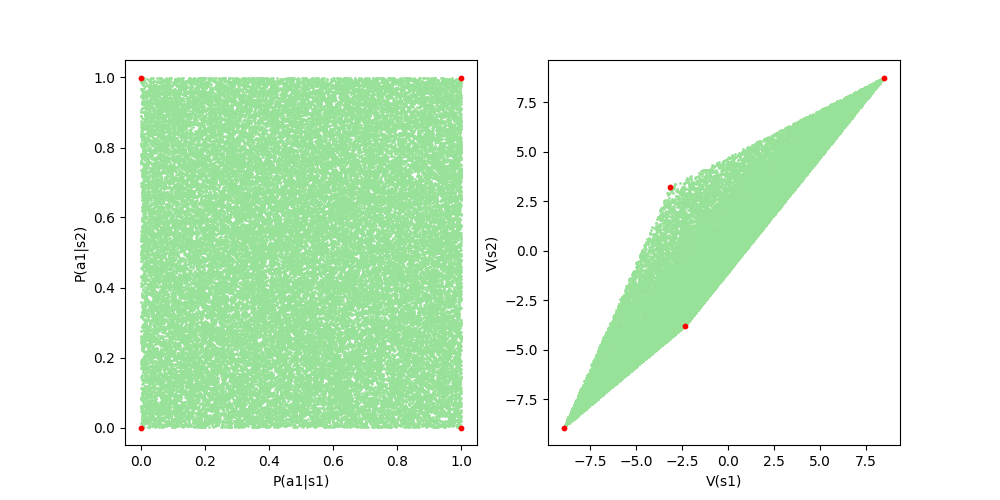
Figure 6: Mapping between sample policies and sample value functions. The red points are the value functions of deterministic policies
To easily visualize the policy space and value function space, 2-state 2-action MDP was used for Figure 6. It includes 50,000 pairs of policy and value function samples. The specific details of MDP presented in this figure are as follows.
The left of Figure 6 definitely shows that the policy has been sampled uniformly. Despite the uniformly selected policies, you can still see the sparse empty space in the upper left corner of the value function space. Also, to confirm the existence of the polytope's vertex, I took the value functions of deterministic policies and confirmed that they become the vertex. In conclusion, we can know that the sparse empty space in the figure is simply due to the lack of sample numbers. It can also be seen that the polytope of the value function space does not consist of equal density.
Definition 3 : Policy Agreement
Two policies
For a given policy
Definition 4 : Policy Determinism
A policy
-deterministic for if . - semi-deterministic if it is
-deterministic for at least one . - deterministic if it is
-deterministic for all states .
We denote by
Value Functions and Policy Agreement
Now, I will introduce one of the most amazing theorem of this paper, line theorem. It characterizes the subsets of value function space that are generated by the policies which agree on all but one state. Surprisingly, it describes a line segment within the value function polytope and this line segment is monotone.
Theorem 1 : Line Theorem
Let
Furthermore, the image of
Furthermore, the image of
Theorem 1 implies that we can generate
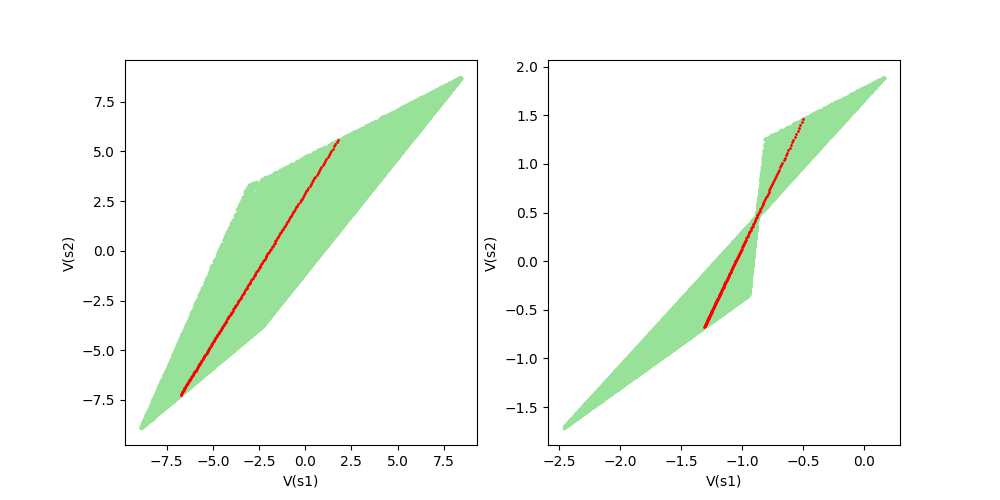
Figure 7: Illustration of Theorem 1 Line Theorem.
Figure 7 actually illustrates the value function space drawn by the interpolated policies between
Figure 7: Left
Figure 7: Right
For both figures in Figure 7, the following
where
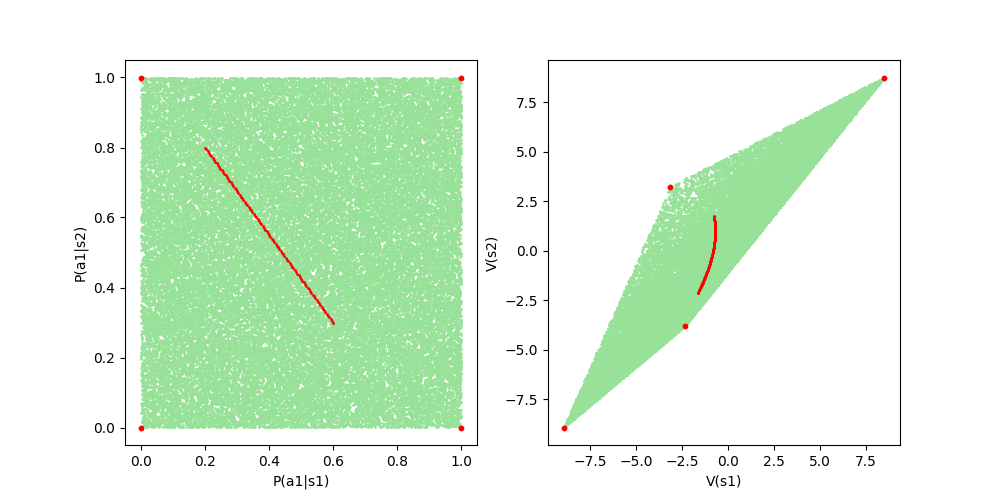
Figure 8: Value functions of mixtures of two policies in the general case.
The red points in Figure 8 are the value functions of mixtures of two policies. You can see that the red points are curved, not straight. It can be seen that the condition, the policies should agree on all but one state, is a necessary condition.
By visualizing the policy space, we can easily recognize that the two policies do not agree on any states. In the case of
Corollary 1.* *For any set of states
Corollary 1 can be proved by mathematical induction on the number of states
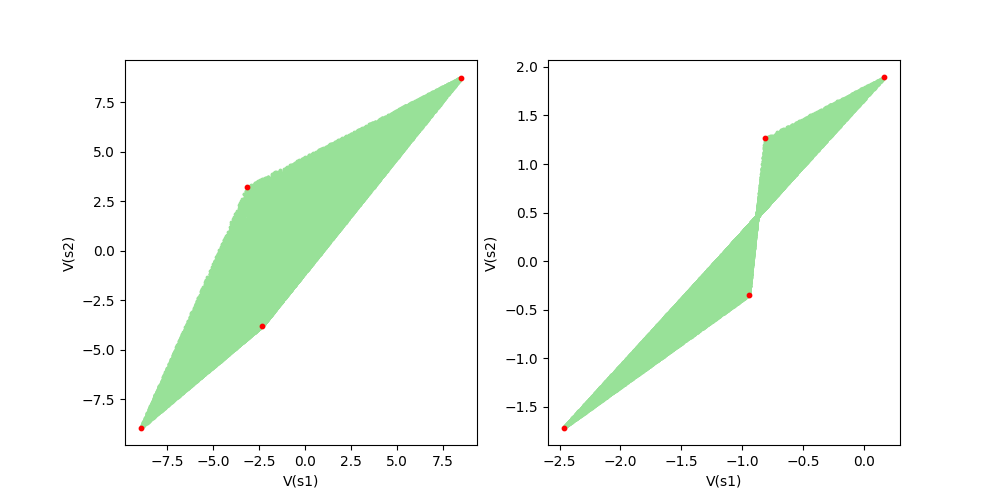
Figure 9: Visual representation of Corollary 1. The red dots are the value functions of deterministic policies.
As you can see in Figure 9, the space of value functions is included in the convex hull of value functions of deterministic policies. Also, you can check the relationship between the vertices of
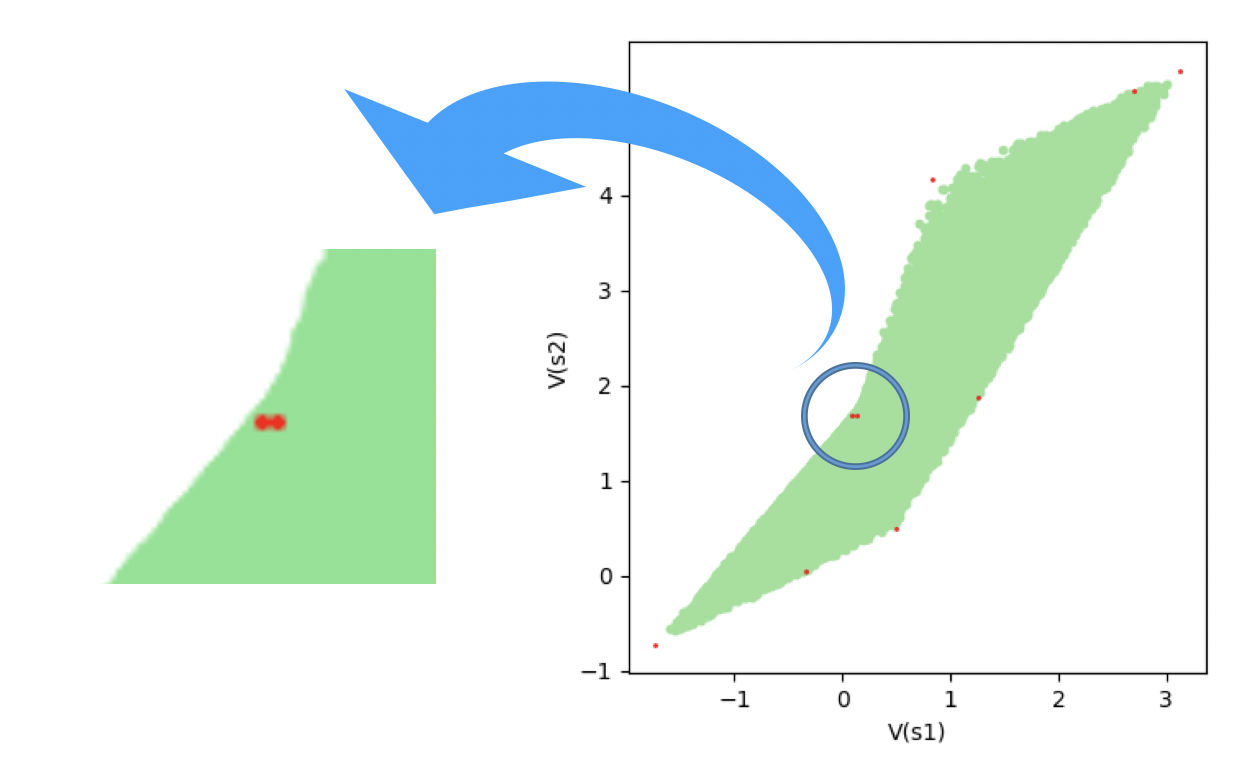
Figure 10: Visual representation of Corollary 1. The value functions of deterministic policies are not identical to the vertices of V.
The Boundary of
Theorem 2 and Corollary 3 show that the boundary of value function space is described by semi-deterministic policies.
Let's start with first defining the affine vector space before we mention Theorem 2. Consider a policy
where
Theorem 2.
Consider the ensemble of policies
Corollary 3.* *Consider a policy
where
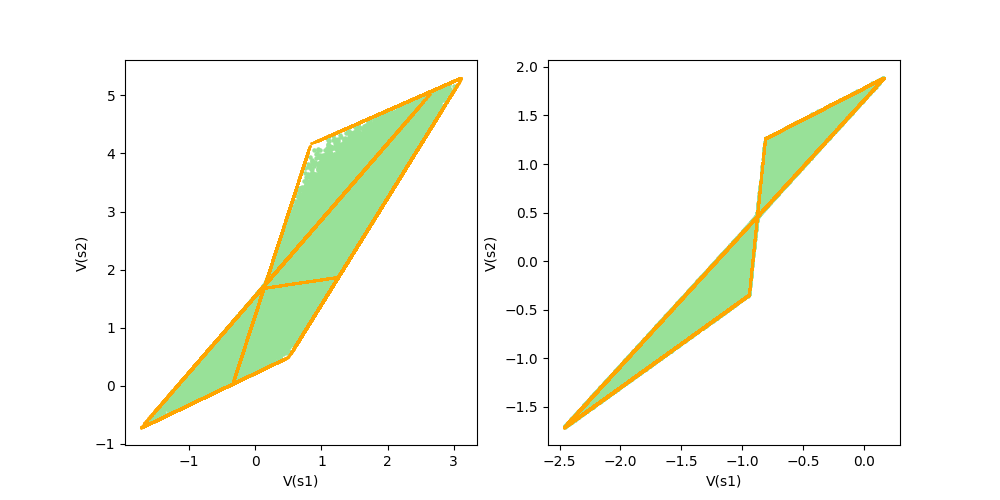
Figure 11: Visual representation of Corollary 3. The orange points are the value functions of semi-deterministic policies.
The Polytope of Value Functions
By combining all the previous results, Dadashi et al 1 proved the value function space
Theorem 3.
Consider a policy
Theorem 3 can be proved by induction on
5. Summary
There have been many developments in the field of value function geometry recently. In the case of finite state-action spaces, Dadashi et al 1 characterized the shape of value function space: a general polytope. It helps our understanding of the dynamics of reinforcement learning algorithms.
Although there is still a problem with generalizing to infinite or continuous state-action spaces, it is certain to be a great study that has created a new direction exploring the field of reinforcement learning. Bellemare et al 4 discovered a connection between representation learning and the polytopal structure of value functions, and a number of follow-up papers are being published 7 8. Also, exploring the relationship between value function approximation and the geometry of value functions will be another interesting field of study.
Before joining ML2, I did not have a good understanding of reinforcement learning. However, thanks to all of the members of ML2, I was able to gain valuable research experience in reinforcement learning and the field of value function geometry during my internship. I am still deeply interested in developing the research during my internship.
Reference
1
Dadashi, R., Taiga, A. A., Roux, N.L., Schuurmans, D., and Bellemare, M. G.
The value function polytope in reinforcement learning, In ICML, 2019.
2
Sutton, R. S. and Barto, A. G.
Reinforcement Learning: An Introduction, MIT Press, 2nd edition, 2018.
3
Poupart, P. and Boutilier, C.
Value-Directed Belief State Approximation for POMDPs,arXiv preprint arXiv:1301.3887, 2013.
4
Bellemare, M. G., Dabney, W., Dadashi, R., Taiga, A. A., Castro, P. S., Roux, N. L., Schuurmans, D., Lattimore, T., and Lyle, C.
A geometric perspective on optimal representations for reinforcement learning, In Neural Information Processing Systems (NeurIPS), 2019.
5
Rao, A.
Value Function Geometry and Gradient TD, Stanford CME 241 Lecture Slides, 2020.
6
Ziegler, G. M.
Lectures on Polytopes, volume 152. Springer Science & Business Media, 2012.
7
Dabney, W., Barreto, A., Rowland, M., Dadashi, R., Quan, J., Bellemare, M. G. and Silver, D.
The Value-Improvement Path Towards Better Representations for Reinforcement Learning, arXiv preprint arXiv:2006.02243, 2020.
8
Ghosh, D. and Bellemare, M. G.
Representations for Stable Off-Policy Reinforcement Learning, arXiv preprint arXiv:2007.05520, 2020.






