#Computer Vision
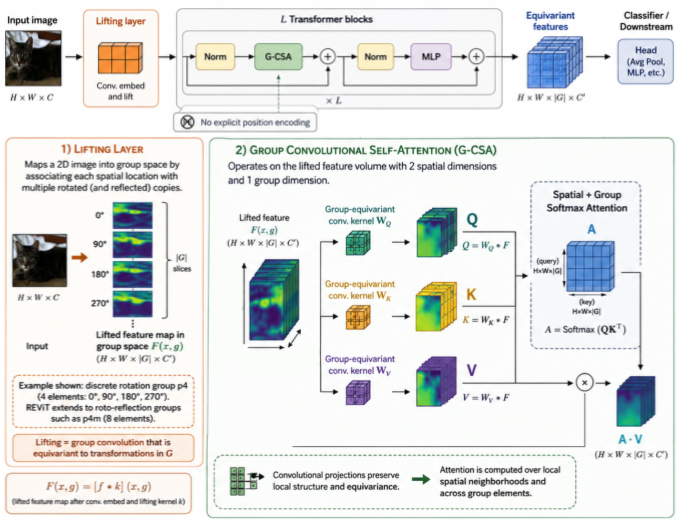
REViT: Roto-reflection Equivariant Convolutional Vision Transformer
ICML 2026
2026.06.24
#AI4Science
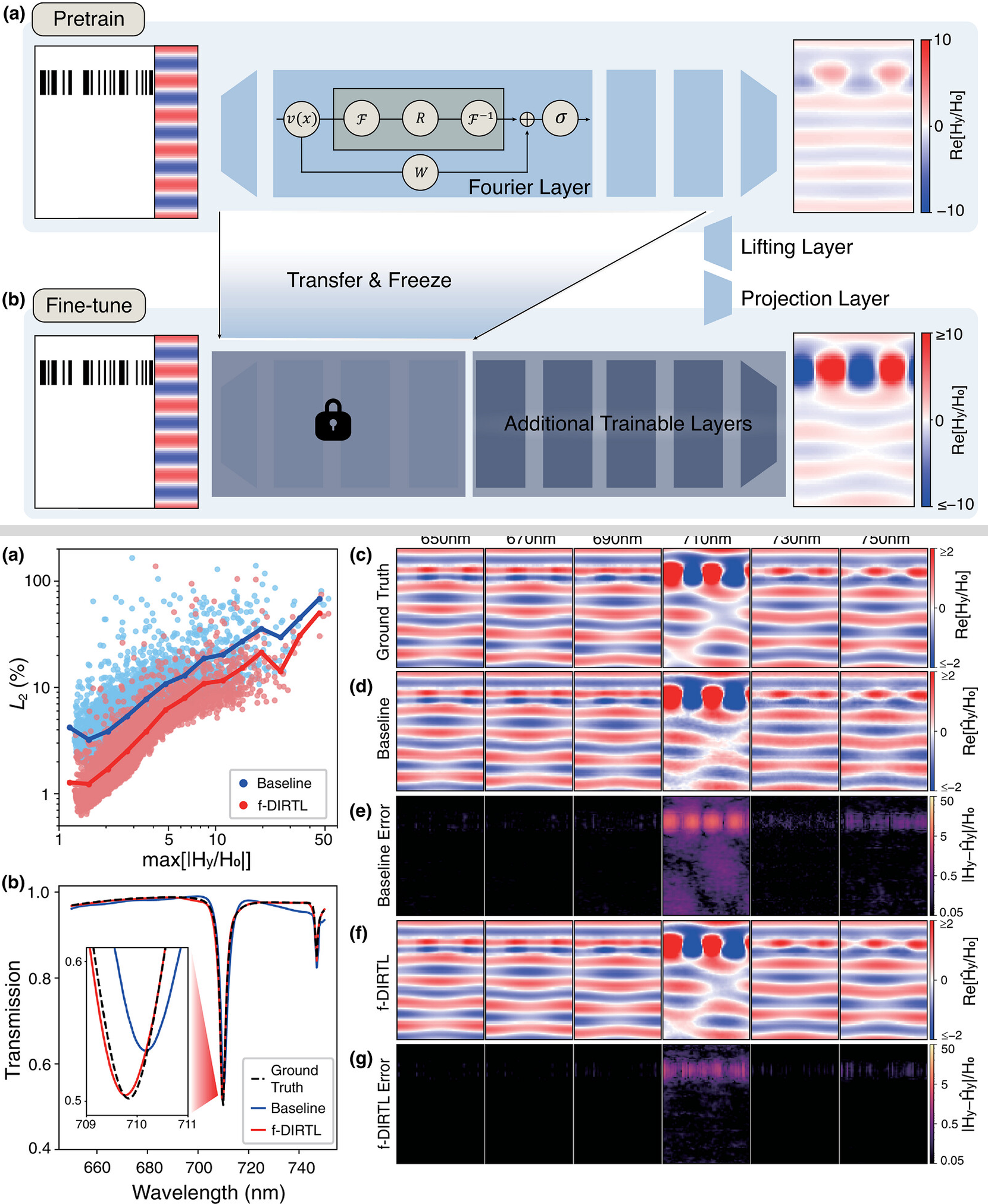
Data-Efficient Electromagnetic Surrogate Solver Through Dissipative Relaxation Transfer Learning
Advanced Optical Materials
2026.06.18
#Robotics #Open Source
NavOCR: Lightweight Text Detection for Navigation
ROSCon Korea 2026
2026.01.22

#Computer Vision
Group Convolutional Self-Attention for Roto-Translation Equivariance in ViTs
NeurIPS Workshops 2025
2025.12.07

Our results demonstrate the competitive performance of our approach in comparison to the existing approaches with significantly smaller model sizes and complexity.
#Computer Vision
ErA: Error-Aware Deep Unrolling Network for Single Image Defocus Deblurring
NeurIPS Workshops 2025
2025.12.06

TL;DR
ErA is a new deep-unrolling network for single-image defocus deblurring that corrects kernel estimation errors on the fly.
#LLM #RAG #Open Source #ML Applications
MARU-Lang (Open-source RAG Chatbot Engine)
Open Source Summit Korea 2025
2025.11.05
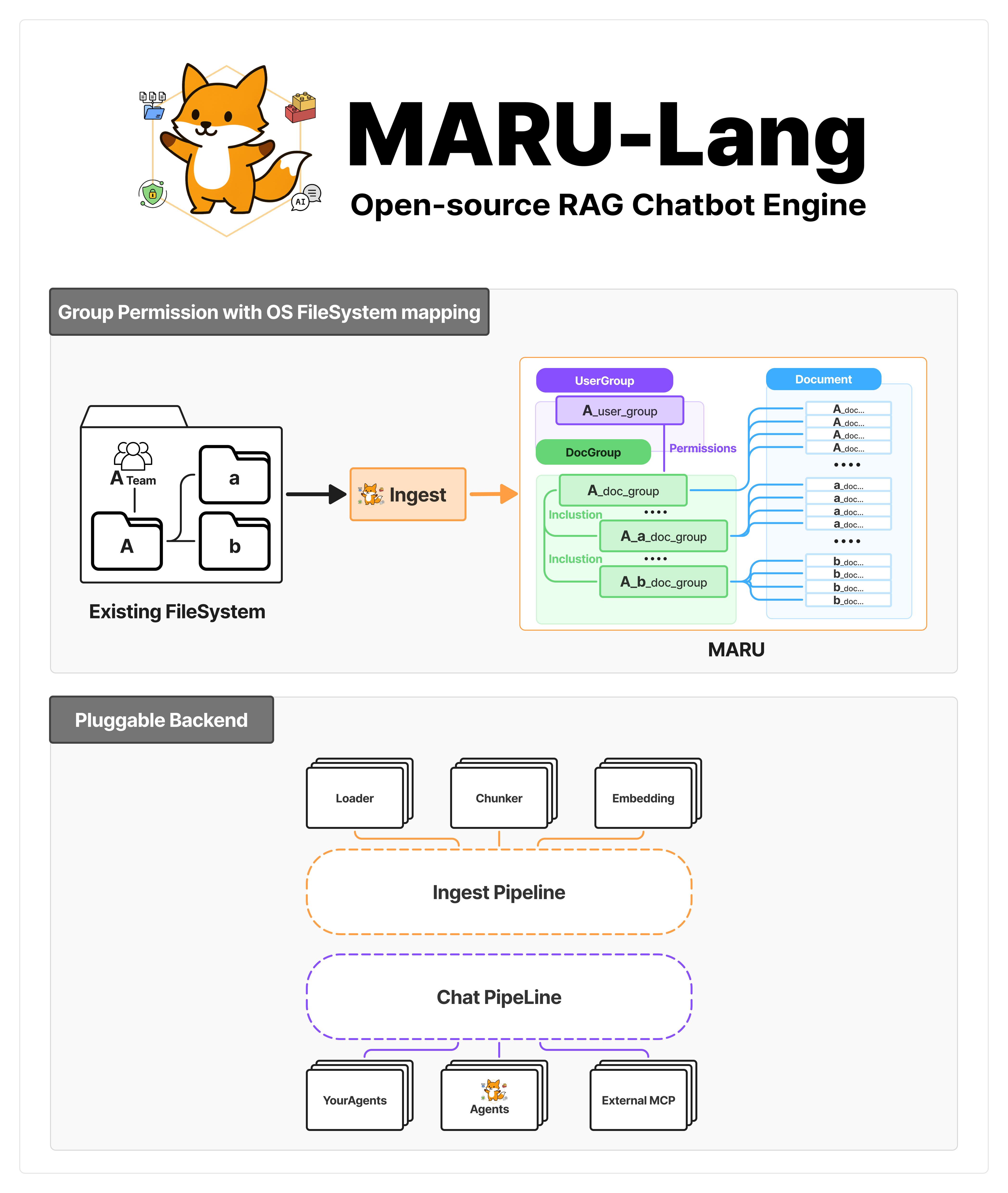
To provide seamless user experiences and easy compatibility with enterprise infrastructure, MARU is designed to align with corporate document management and access systems. We open-sourced MARU to help developers who face similar real-world challenges in enterprise AI integration.
#LLVM #MLIR #Open Source
Optimizing IREE to Match llama.cpp: An Introduction to IREE optimization for newbies through a benchmark journey
2025 US LLVM Developers Meeting
2025.10.29

#Computer Vision
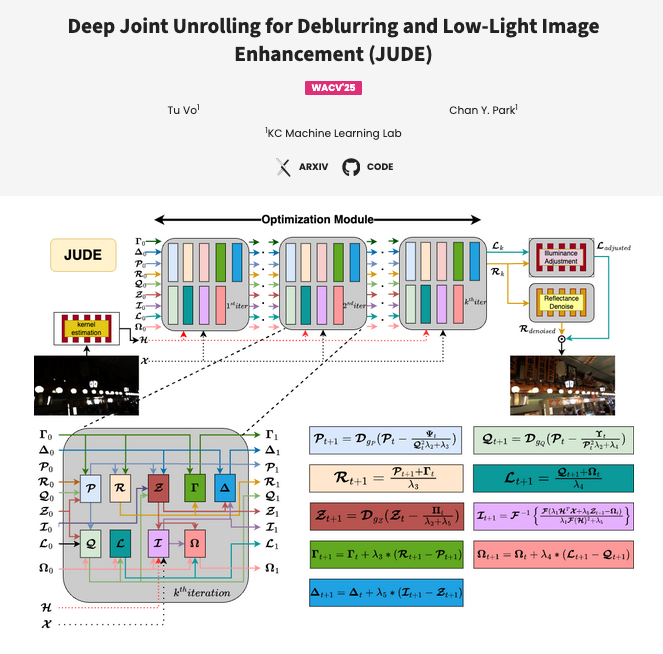
Deep Joint Unrolling for Deblurring and Low-Light Image Enhancement (JUDE)
WACV 2025
2024.12.10
#Robotics #ML Applications
Enhancing OCR-based Indoor Place Recognition with Visitor Map Image by Mitigating Noise from Distracting Words
IROS 2024
2024.10.14

#Reinforcement Learning #AI4Science
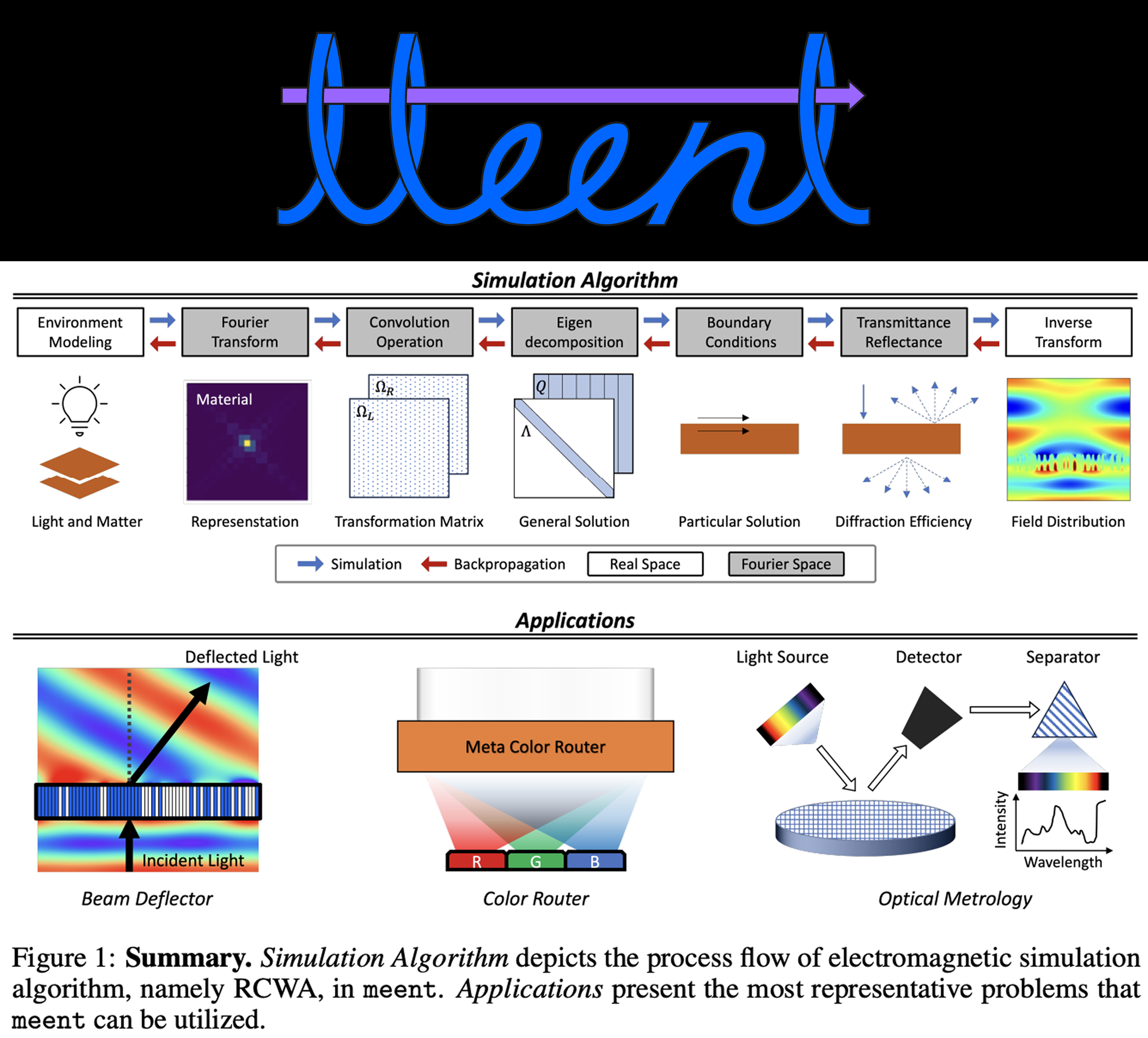
Meent: Differentiable Electromagnetic Simulator for Machine Learning
2024.06.11
#Reinforcement Learning #AI4Science
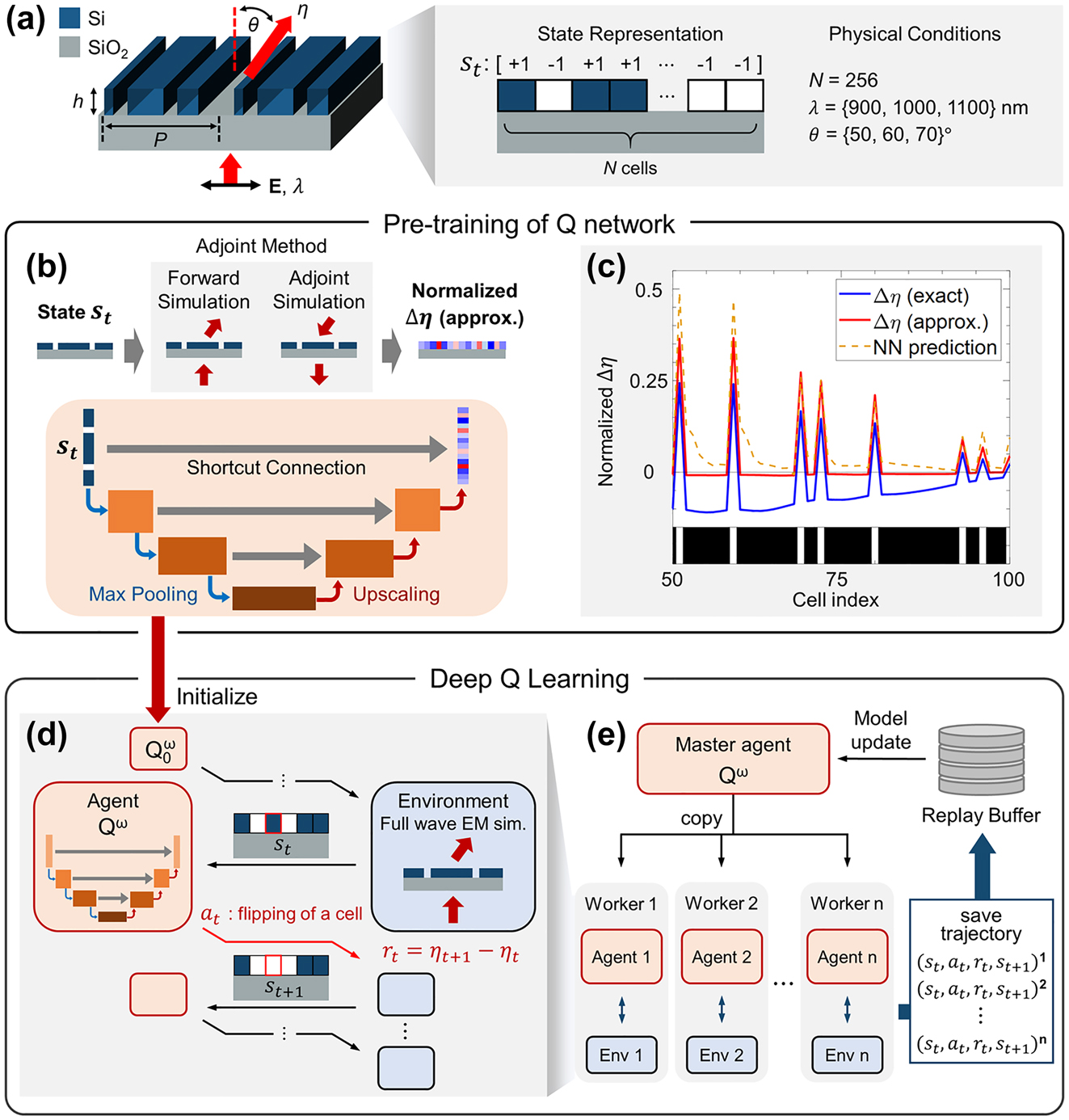
Sample-efficient inverse design of freeform nanophotonic devices with physics-informed reinforcement learning
Nanophotonics 2024
2024.02.27
#Computer Vision
In-Season Wall-to-Wall Crop-Type Mapping Using Ensemble of Image Segmentation Models
IEEE Transactions on Geoscience and Remote Sensing (Volume 61)
2023.12.01
#Computer Vision
RCV2023 Challenges: Benchmarking Model Training and Inference for Resource-Constrained Deep Learning
ICCV 2023 workshop
2023.10.02
#Graph #Open Source #ML Applications
LLVM-FLOW
Euro LLVM Developers Meeting 2023
2023.05.11
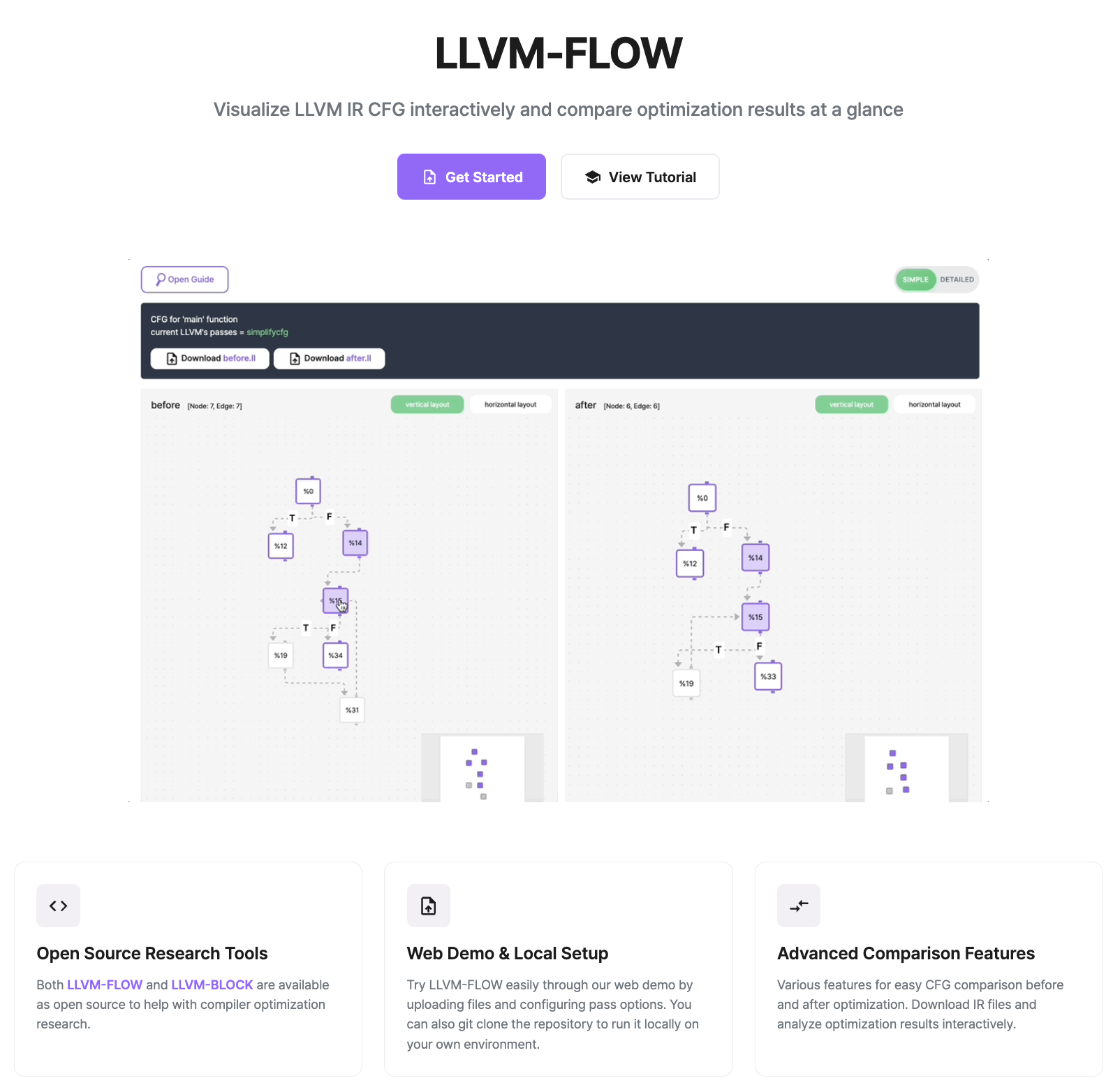
LLVM-FLOW is a useful tool not only for experienced LLVM developers seeking to better understand the IR flow when writing custom passes, but also for newcomers to the LLVM ecosystem who wish to study the behavior of IR patterns.
#AI4Science
Free-form optimization of nanophotonic devices: from classical methods to deep learning
Nanophotonics 2022
2022.01.12
#Reinforcement Learning #AI4Science
Structural optimization of a one-dimensional freeform metagrating deflector via deep reinforcement learning
ACS Photonics 2022
2021.12.30

#AI4Science
Inverse design of organic light-emitting diode structure based on deep neural networks
Nanophotonics 2021
2021.11.04
#Reinforcement Learning #Publications
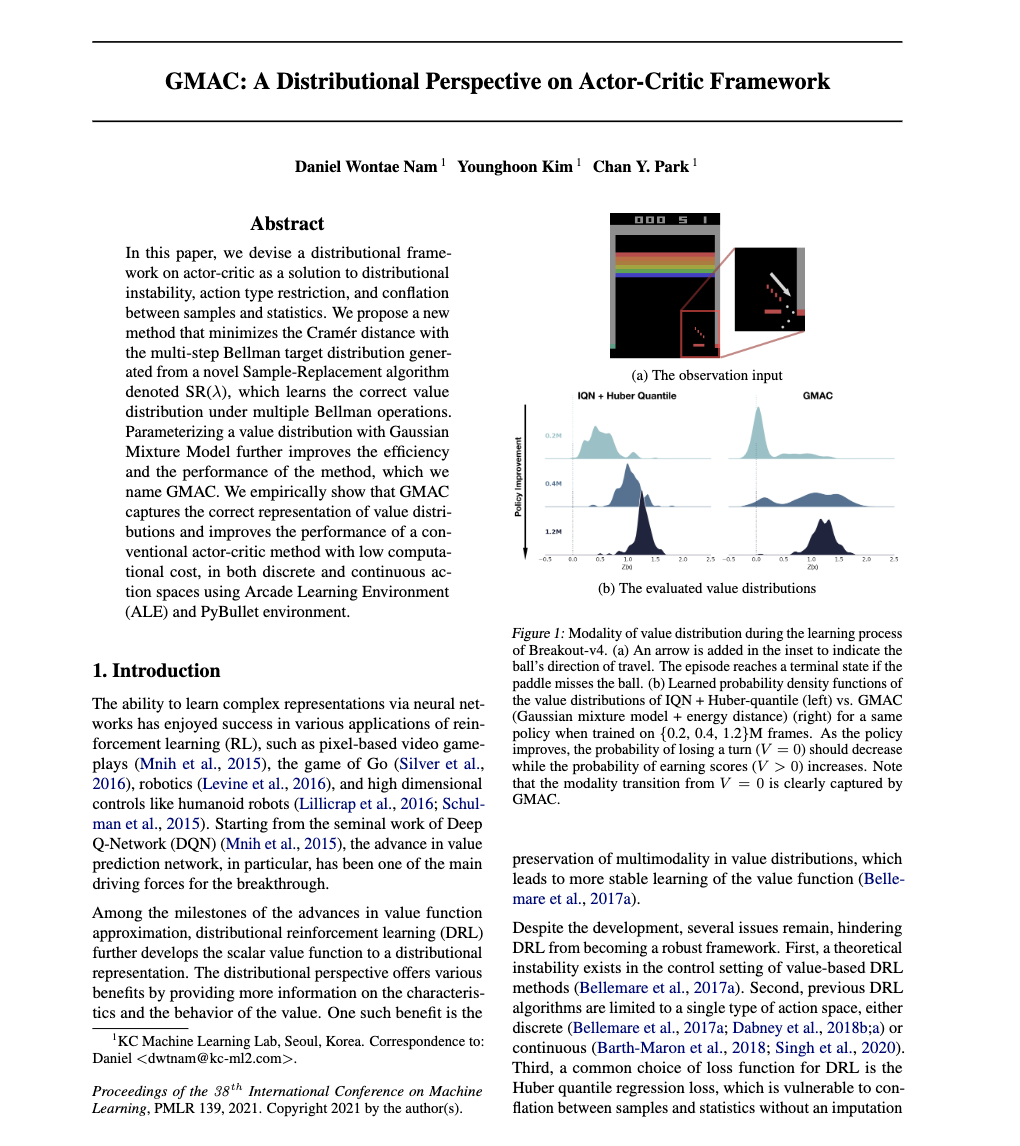
GMAC: A Distributional Perspective on Actor-Critic Framework
ICML 2021
2021.09.13
#Reinforcement Learning #Open Source
MAS tutorials
2021.06.15
#Reinforcement Learning #Open Source
Reinforcement learning library (RL2)
2020.10.28
#Reinforcement Learning #Open Source
ML2 multiagent RL mini-game environments
2020.04.28
#Graph #Open Source #ML Applications
LLVM-Block
2020.04.17
#Computer Vision
Investigating Pixel Robustness using Input Gradients
2019.08.30
#Reinforcement Learning
Distilling Curiosity for Exploration
2019.07.29